
7x8 Bathroom Layout
- Home
- sumouli.choudhary
- Subjective Answers
thumb_up 1 thumb_down 0 flag 0
What is MySQL?
MySQL is a popular open-source relational database management system (RDBMS) that is developed, distributed and supported by Oracle Corporation. Like other relational systems, MySQL stores data in tables and uses structured query language (SQL) for database access. In MySQL, you pre-define your database schema based on your requirements and set up rules to govern the relationships between fields in your tables. In MySQL, related information may be stored in separate tables, but associated through the use of joins. In this way, data duplication is minimized.
What is MongoDB?
MongoDB is an open-source database developed by MongoDB, Inc. MongoDB stores data in JSON-like documents that can vary in structure. Related information is stored together for fast query access through the MongoDB query language. MongoDB uses dynamic schemas, meaning that you can create records without first defining the structure, such as the fields or the types of their values. You can change the structure of records (which we call documents) simply by adding new fields or deleting existing ones. This data model give you the ability to represent hierarchical relationships, to store arrays, and other more complex structures easily. Documents in a collection need not have an identical set of fields and denormalization of data is common. MongoDB was also designed with high availability and scalability in mind, and includes out-of-the-box replication and auto-sharding.
Terminology and Concepts
Many concepts in MySQL have close analogs in MongoDB. This table outlines some of the common concepts in each system.
MySQL MongoDB
Table Collection
Row Document
Column Field
Joins Embedded documents, linking
Feature Comparison
Like MySQL, MongoDB offers a rich set of features and functionality far beyond those offered in simple key-value stores. MongoDB has a query language, highly-functional secondary indexes (including text search and geospatial), a powerful aggregation framework for data analysis, and more. With MongoDB you can also make use of these features across more diverse data types than with a relational database, and at scale.
Properties MySQL MongoDB
1. Rich Data Model No Yes
2. Dynamic Schema No Yes
3. Typed Data Yes Yes
4. Data Locality No Yes
5. Field Updates Yes Yes
6. Easy for Programmers No Yes
7. Complex Transactions Yes No
8. Auditing Yes Yes
9. Auto-Sharding No Yes
thumb_up 2 thumb_down 1 flag 0
If you don't want users of your class to be able to assign objects of its type (password string objects are a good example), you can declare a private assignment operator and copy constructor. Please note that the compiler-synthesized copy constructor and assignment operator are public, therefore, you have to define them explicitly as private members in this case. For example:
class NoCopy { private: NoCopy& operator = (const NoCopy& other) { /*..*/} NoCopy(const NoCopy& other) {/*..*/} public: //... }; void f() { NoCopy nc; //fine, default constructor called NoCopy nc2(nc); //compile time error; attempt to call a private copy constructor nc2 = nc; //also a compile time error; operator= is private } thumb_up 2 thumb_down 0 flag 0
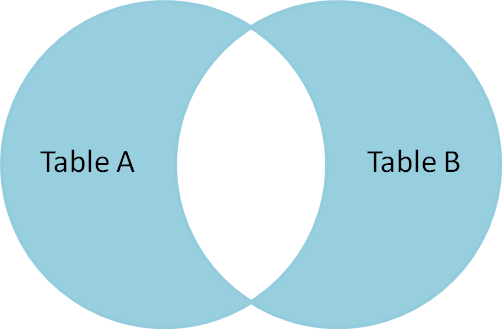
Assume we have the following two tables.Table A is on the left, andTable B is on the right. We'll populate them with four records each.
id name id name -- ---- -- ---- 1 Pirate 1 Rutabaga 2 Monkey 2 Pirate 3 Ninja 3 Darth Vader 4 Spaghetti 4 Ninja
Let's join these tables by the name field in a few different ways and see if we can get a conceptual match to those nifty Venn diagrams.
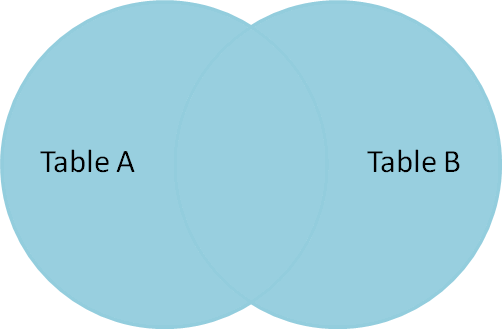
SELECT * FROM TableA INNER JOIN TableB ON TableA.name = TableB.name id name id name -- ---- -- ---- 1 Pirate 2 Pirate 3 Ninja 4 Ninja
Inner join produces only the set of records that match in both Table A and Table B.
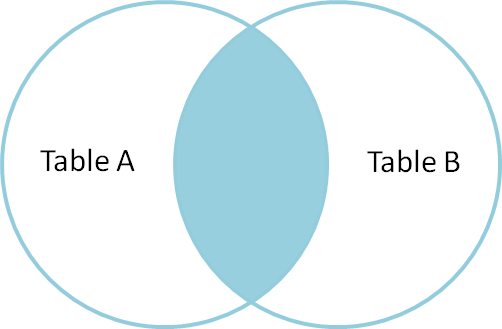
SELECT * FROM TableA FULL OUTER JOIN TableB ON TableA.name = TableB.name id name id name -- ---- -- ---- 1 Pirate 2 Pirate 2 Monkey null null 3 Ninja 4 Ninja 4 Spaghetti null null null null 1 Rutabaga null null 3 Darth Vader
Full outer join produces the set of all records in Table A and Table B, with matching records from both sides where available. If there is no match, the missing side will contain null.
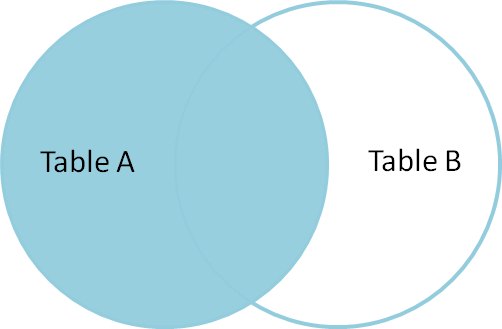
SELECT * FROM TableA LEFT OUTER JOIN TableB ON TableA.name = TableB.name id name id name -- ---- -- ---- 1 Pirate 2 Pirate 2 Monkey null null 3 Ninja 4 Ninja 4 Spaghetti null null
Left outer join produces a complete set of records from Table A, with the matching records (where available) in Table B. If there is no match, the right side will contain null.
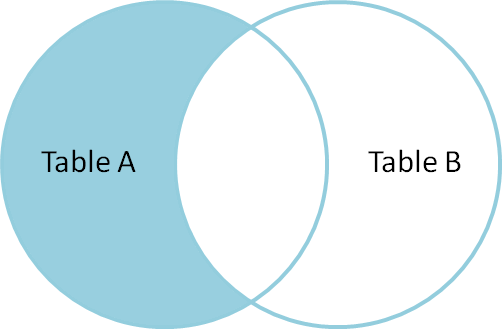
SELECT * FROM TableA LEFT OUTER JOIN TableB ON TableA.name = TableB.name WHERE TableB.id IS null id name id name -- ---- -- ---- 2 Monkey null null 4 Spaghetti null null
To produce the set of records only in Table A, but not in Table B, we perform the same left outer join, thenexclude the records we don't want from the right side via a where clause.
SELECT * FROM TableA FULL OUTER JOIN TableB ON TableA.name = TableB.name WHERE TableA.id IS null OR TableB.id IS null id name id name -- ---- -- ---- 2 Monkey null null 4 Spaghetti null null null null 1 Rutabaga null null 3 Darth Vader
To produce the set of records unique to Table A and Table B, we perform the same full outer join, thenexclude the records we don't want from both sides via a where clause.
There's also a cartesian product orcross join, which as far as I can tell, can't be expressed as a Venn diagram:
SELECT * FROM TableA CROSS JOIN TableB
This joins "everything to everything", resulting in 4 x 4 = 16 rows, far more than we had in the original sets. If you do the math, you can see why this is avery dangerous join to run against large tables.
thumb_up 2 thumb_down 0 flag 0
What is Node.JS & why it is popular?
- An important thing to realize is that Node is not aweb server. By itself it doesn't do anything.It doesn't work like Apache.There is no config file where you point it to your HTML files.
- If you want it to be a HTTP server,you have to write an HTTP server by using its built in libraries.Node.JS is just another way to execute code in your computer. It is simply aJavaScript run-time.
Node.JS using the 'HTTP' module can run on a stand-alone web server. It is asynchronous, event driven I/O. Every nodes instance runs in a single thread, so it can handle more number of concurrent requests as compared to Apache.

What makes Node.JS fast?
First, Node is powered by Google's V8 JavaScript Engine. The thing running you JavaScript code is the exact same thing the Chrome browser uses to run JavaScript code.
Now Question is why V8 JavaScript Engine?
-It has unique speed compare to other JavaScript engines, it compiles JavaScript directly into native machine code, while other languages PHP & Ruby, Java all have to run through an interpreter every time when they are accessed. Node will run your code as though it's native application. So it screams with speed.
Second, How fastly Node handles connections.

When 100 people connect at once, rather than having different threads, Node will loop over those connections and fire off any events your code should know about. If a connection is new it will tell you .If a connection has sent you data, it will tell you .If the connection isn't doing anything ,it will skip over it rather than taking up precision CPU time on it. Everything in Node is based on responding to these events. So we can see the result, the CPU stay focused on that one process and doesn't have a bunch of threads for attention.There is no buffering in Node.JS application it simply output the data in chunks.
Examples where Node.JS can be use
-Server side web application
-Chat application
-Data Streaming,etc.
thumb_up 1 thumb_down 0 flag 0
On UNIX, there is no enforced relation between parent and child process's lifetimes. Strictly speaking, process will only terminate when they call exit() or receive an unhandled signal for which default action is to terminate.
However, an entire "foreground process group" in a "controlling terminal" can receive signals like SIGINT and SIGQUIT when the user hits ctrl-C, ctrl-\, etc. on that terminal.
thumb_up 2 thumb_down 0 flag 0
The__syncthreads() command is ablock level synchronization barrier. That means it is safe to be used when all threads in a block reach the barrier. It is also possible to use__syncthreads() in conditional code but only when all threads evaluate identically such code otherwise the execution is likely to hang or produce unintended side effects.
Example of using__syncthreads():
__global__ void globFunction(int *arr, int N) { __shared__ int local_array[THREADS_PER_BLOCK]; //local block memory cache int idx = blockIdx.x* blockDim.x+ threadIdx.x; //...calculate results local_array[threadIdx.x] = results; //synchronize the local threads writing to the local memory cache __syncthreads(); // read the results of another thread in the current thread int val = local_array[(threadIdx.x + 1) % THREADS_PER_BLOCK]; //write back the value to global memory arr[idx] = val; } To synchronize all threads in a grid currently there isnot native API call. One way of synchronizing threads on a grid level is usingconsecutive kernel calls as at that point all threads end and start again from the same point. It is also commonly called CPU synchronization or Implicit synchronization. Thus they are all synchronized.
Example of using this technique :

thumb_up 5 thumb_down 0 flag 0
CUDA is a parallel computing platform and programming model that makes using a GPU for general purpose computing simple and elegant. The developer still programs in the familiar C, C++, Fortran, or an ever expanding list of supported languages, and incorporates extensions of these languages in the form of a few basic keywords.
These keywords let the developer express massive amounts of parallelism and direct the compiler to the portion of the application that maps to the GPU.
A simple example of code is shown below. It's written first in plain "C" and then in "C with CUDA extensions."

thumb_up 3 thumb_down 0 flag 0
The following are the 6 high level stages of a typical Linux boot process.

1. BIOS
- BIOS stands for Basic Input/Output System
- Performs some system integrity checks
- Searches, loads, and executes the boot loader program.
- It looks for boot loader in floppy, cd-rom, or hard drive. You can press a key (typically F12 of F2, but it depends on your system) during the BIOS startup to change the boot sequence.
- Once the boot loader program is detected and loaded into the memory, BIOS gives the control to it.
- So, in simple terms BIOS loads and executes the MBR boot loader.
2. MBR
- MBR stands for Master Boot Record.
- It is located in the 1st sector of the bootable disk. Typically /dev/hda, or /dev/sda
- MBR is less than 512 bytes in size. This has three components 1) primary boot loader info in 1st 446 bytes 2) partition table info in next 64 bytes 3) mbr validation check in last 2 bytes.
- It contains information about GRUB (or LILO in old systems).
- So, in simple terms MBR loads and executes the GRUB boot loader.
3. GRUB
#boot=/dev/sda default=0 timeout=5 splashimage=(hd0,0)/boot/grub/splash.xpm.gz hiddenmenu title CentOS (2.6.18-194.el5PAE) root (hd0,0) kernel /boot/vmlinuz-2.6.18-194.el5PAE ro root=LABEL=/ initrd /boot/initrd-2.6.18-194.el5PAE.img
- GRUB stands for Grand Unified Bootloader.
- If you have multiple kernel images installed on your system, you can choose which one to be executed.
- GRUB displays a splash screen, waits for few seconds, if you don't enter anything, it loads the default kernel image as specified in the grub configuration file.
- GRUB has the knowledge of the filesystem (the older Linux loader LILO didn't understand filesystem).
- Grub configuration file is /boot/grub/grub.conf (/etc/grub.conf is a link to this). The following is sample grub.conf of CentOS.
- As you notice from the above info, it contains kernel and initrd image.
- So, in simple terms GRUB just loads and executes Kernel and initrd images.
4. Kernel
- Mounts the root file system as specified in the "root=" in grub.conf
- Kernel executes the /sbin/init program
- Since init was the 1st program to be executed by Linux Kernel, it has the process id (PID) of 1. Do a 'ps -ef | grep init' and check the pid.
- initrd stands for Initial RAM Disk.
- initrd is used by kernel as temporary root file system until kernel is booted and the real root file system is mounted. It also contains necessary drivers compiled inside, which helps it to access the hard drive partitions, and other hardware.
5. Init
- Looks at the /etc/inittab file to decide the Linux run level.
- Following are the available run levels
- 0 – halt
- 1 – Single user mode
- 2 – Multiuser, without NFS
- 3 – Full multiuser mode
- 4 – unused
- 5 – X11
- 6 – reboot
- Init identifies the default initlevel from /etc/inittab and uses that to load all appropriate program.
- Execute 'grep initdefault /etc/inittab' on your system to identify the default run level
- If you want to get into trouble, you can set the default run level to 0 or 6. Since you know what 0 and 6 means, probably you might not do that.
- Typically you would set the default run level to either 3 or 5.
6. Runlevel programs
- When the Linux system is booting up, you might see various services getting started. For example, it might say "starting sendmail …. OK". Those are the runlevel programs, executed from the run level directory as defined by your run level.
- Depending on your default init level setting, the system will execute the programs from one of the following directories.
- Run level 0 – /etc/rc.d/rc0.d/
- Run level 1 – /etc/rc.d/rc1.d/
- Run level 2 – /etc/rc.d/rc2.d/
- Run level 3 – /etc/rc.d/rc3.d/
- Run level 4 – /etc/rc.d/rc4.d/
- Run level 5 – /etc/rc.d/rc5.d/
- Run level 6 – /etc/rc.d/rc6.d/
- Please note that there are also symbolic links available for these directory under /etc directly. So, /etc/rc0.d is linked to /etc/rc.d/rc0.d.
- Under the /etc/rc.d/rc*.d/ directories, you would see programs that start with S and K.
- Programs starts with S are used during startup. S for startup.
- Programs starts with K are used during shutdown. K for kill.
- There are numbers right next to S and K in the program names. Those are the sequence number in which the programs should be started or killed.
- For example, S12syslog is to start the syslog deamon, which has the sequence number of 12. S80sendmail is to start the sendmail daemon, which has the sequence number of 80. So, syslog program will be started before sendmail.
There you have it. That is what happens during the Linux boot process.
thumb_up 1 thumb_down 0 flag 0
If you're doing lots of reads and writes on it, a ConcurrentHashMap is possibly the best choice, if it's mostly reading, a common Map wrapped inside a collection using a ReadWriteLock (since writes would not be common, you'd get faster access and locking only when writing).
Collections.synchronizedMap() is possibly the worst case, since it might just give you a wrapper with all methods synchronized, avoid it at all costs.
thumb_up 1 thumb_down 0 flag 0
Function template defines a general set of operations that will be applied to various types of data. The type of data that the function will operate upon is passed to it as a parameter. Through a generic function, a single general procedure can be applied to a wide range of data. Depending on the program, the compiler creates different versions of function template associated with different data types. Generic function is created using the keyword template. It is used to create a template that describes what a function will do.
E.g. we can write a function template that swaps two numbers. We can use the same template to swap two ints, two floats or even two chars.
#include <iostream> template <class X> void swap(X &a, X &b) // ? Function template { X temp; temp = a; a = b; b = temp; } int main() { int i = 10, j = 20; float x = 4.5, y = 8.7; char a = 'A', b = 'B'; cout << "Original i and j are : "<< i << ' ' << j << '\n'; cout << "Original x and y are : "<< x << ' ' << y << '\n'; cout << "Original a and b are : "<< a << ' ' << b << '\n'; swap(i, j); // we can call the same function with different parameters swap(x, y); // Compiler has created 3 version of template function swap(a, b); //The correct version will be called depending on parameters passed cout << "Swapped i and j are : "<< i << ' ' << j << '\n'; cout << "Swapped x and y are : "<< x << ' ' << y << '\n'; cout << "Swapped a and b are : "<< a << ' ' << b << '\n'; return 0; } thumb_up 5 thumb_down 1 flag 0
after 7! i.e from 8! to 58 ! every number is divisible by 56 (as they all have 7x8 as one factor), so 8!+...58! gives remainder 0 when divided by 56 .
Even 7! (7x6x5x4x3x2) contains 7 and 8 (4x2) is also divisible by 56 and gives remainder 0.
Now 1!+2!+...+6!=1+2+6+24+120+720 = 873 %56 = 33
Hence ans is 33
thumb_up 0 thumb_down 0 flag 0
PHP
PHP is the Hypertext Preprocessor scripting language for making scalable, dynamic web applications. It is released in 1995 and considered as a number one backend development language for over past 20 years.
Node.JS
Node.JS is a platform built on Chrome's v8 Javascript for easily building fast, scalable, network applications rather than the traditional approach of threading. It is released in 2009 and considered as a popular platform that is defining the new web future.
Why PHP?
PHP is advisable for making high-level web applications because
- It has a huge community. PHP has an experienced guidance because of the huge development era. That is why you can get any solution for your problem very easily.
- It is a deep code based, means most of the Content Management Systems (like Joomla, WordPress, Magento, Drupal) are purely PHP based.
- PHP is more common for hosting providers. This is because there is no compatibility issue to make application live on the server.
- The simplicity of the PHP code, it can run as HTML by changing extension of it.
- No jar, preprocessor, no compiler and deployment dependency exists.
- You can add php anywhere in your code by just using tag , that makes PHP more flexible.
Why not PHP?
Now, the trend is going in a way that most of the Startups are not using PHP as their Tech Stack because,
- It is relatively slower than the advanced server-side development competitors like Node.
- Since it is open sourced, so anyone can access it. If there are bugs in the source code, it can be used by people to explore the weakness of PHP.
- It is not suitable for making larger applications; it is ideally suited for e-commerce based applications.
Why Node?
Most of the Startups are prioritizing Node over other monolithic stacks like PHP, or Ruby on Rails, because
- Extraordinary faster than PHP because of the event callback mechanism.
- Primarily, it has single-threaded mechanism, but you can also scale Node app on multi-core system. For more information about scaling, see my other article.
- It has separation of concerns, i.e, separate modules for any operation.
- Node.JS is popular, new and fresh.
- It uses callback structure to pass logic from one call to another.
- Less or relatively no chances of occurrence of deadlock mechanism.
- It can use the single as well as multi-threaded application
- Anyone with another platform background can jump to Node. It has numerous frameworks which can be used as an alternate for other frameworks like Ruby on Rails.
Why not Node?
Although, Node is providing the best possible solution, but there are always two sides of the mirror. Wisely think when making a Node application because
- Node is not suitable for processor intensive tasks.
- Any CPU-intensive code makes it really non-scalable.
thumb_up 1 thumb_down 0 flag 0
Approaches for the puzzle :
8/(1 – 1/5) = 10
OR
8 ÷ (1 – 1 ÷ 5) = 10
thumb_up 4 thumb_down 0 flag 0
Stack:
- Stored in computer RAM just like the heap.
- Variables created on the stack will go out of scope and automatically deallocated.
- Much faster to allocate in comparison to variables on the heap.
- Implemented with an actual stack data structure.
- Stores local data, return addresses, used for parameter passing
- Can have a stack overflow when too much of the stack is used. (mostly from infinite (or too much) recursion, very large allocations)
- Data created on the stack can be used without pointers.
- You would use the stack if you know exactly how much data you need to allocate before compile time and it is not too big.
- Usually has a maximum size already determined when your program starts
Heap:
- Stored in computer RAM just like the stack.
- In C++, variables on the heap must be destroyed manually and never fall out of scope. The data is freed with
delete,delete[], orfree - Slower to allocate in comparison to variables on the stack.
- Used on demand to allocate a block of data for use by the program.
- Can have fragmentation when there are a lot of allocations and deallocations
- In C++ or C, data created on the heap will be pointed to by pointers and allocated with
newormallocrespectively. - Can have allocation failures if too big of a buffer is requested to be allocated.
- You would use the heap if you don't know exactly how much data you will need at run time or if you need to allocate a lot of data.
- Responsible for memory leaks
Example:
int foo() { char *pBuffer; //<--nothing allocated yet (excluding the pointer itself, which is allocated here on the stack). bool b = true; // Allocated on the stack. if(b) { //Create 500 bytes on the stack char buffer[500]; //Create 500 bytes on the heap pBuffer = new char[500]; }//<-- buffer is deallocated here, pBuffer is not }//<--- oops there's a memory leak, I should have called delete[] pBuffer; When to use the Heap?
If you need to allocate a large block of memory (e.g. a large array, or a big struct), and you need to keep that variable around a long time (like a global), then you should allocate it on the heap.
If you are dealing with relatively small variables that only need to persist as long as the function using them is alive, then you should use the stack, it's easier and faster.
If you need variables like arrays and structs that can change size dynamically (e.g. arrays that can grow or shrink as needed) then you will likely need to allocate them on the heap, and use dynamic memory allocation functions likemalloc(),calloc(),realloc() andfree() to manage that memory "by hand".
thumb_up 5 thumb_down 0 flag 0
Take any one of the three sides and divide it into 5 parts. Now join these line segments to the third vertex. You can form five triangles with equal areas.
How did this work?
Area of a triangle depends on its base and height.
(1) All the five triangles have the same height (perpendicular distance between base and opposite vertex).
(2) Since we divided the side into five equal parts, the base will be same for all of them.
thumb_up 1 thumb_down 0 flag 0
1. If your program allocates a lot of memory, you may need to increase this value to give more room to the garbage collector.
When starting the JVM, two parameters can be adjusted to suit your memory needs :
-Xms<size> specifies the initial Java heap size and
-Xmx<size> the maximum Java heap size.
To set the minimum at 64Mb and the maximum at 256Mb
java -Xms64m -Xmx256m ...
The default value for the minimum is 2Mb, for the maximum it's 64Mb.
2. If you are using Eclipse then you can do this by specifying the required size for the particular application in its Run Configuration's VM Arguments as EX:-Xms128m -Xmx512m
Or if you want all applications running from your eclipse to have the same specified size then you can specify this in theeclipse.ini file which is present in your Eclipse home directory.
To get the size of the JVM during Runtime you can useRuntime.totalMemory() which returns the total amount of memory in the Java virtual machine, measured in bytes.
thumb_up 1 thumb_down 0 flag 0
What is Memory Leak?
Memory leak is a bug that mainly occurs when a program does not release the memory it has obtained for temporary use. In other words we can say it is the condition where the available computer memory reduces gradually there by resulting in poor performance.
How to determine if Memory Leak exists in a Java application?
If the application throws java.lang.OutOfMemoryError or if the program takes more time to execute than is required normally then there could be a memory leak in the application. There are various third party tools to detect and fix memory leaks but it is always better to prevent one from happening
How to avoid Memory Leak in Java?
While coding if we take care of a few points we can avoid memory leak issue.
1. Use time out time for the session as low as possible.
2. Release the session when the same is no longer required. We can release the session by using HttpSession.invalidate().
3. Try to store as less data as possible in the HttpSession.
4. Avoid creating HttpSession in jsp page by default by using the page directive
<%@page session="false"%>
5. Try to use StringBuffer's append() method instead of string concatenation.
String is an immutable object and if we use string concatenation, it will unnecessarily create many temporary objects on heap which results in poor performance.
For ex. if we write String query = "SELECT id, name FROM t_customer whereMsoNormal" style="margin-bottom: 0.0001pt;"> it will create 4 String Objects. But if we write the same query using StringBuffer's append() it will create only one object as StringBuffer is mutable i.e. can be modified over and over again.
6. In JDBC code, While writting the query try to avoid "*". It is a good practice to use column name in select statement.
7. Try to use PreparedStatement object instead of Statement object if the query need to be executed frequently as PreparedStatement is a precompiled SQL statement where as Statement is compiled each time the Sql statement is sent to the database.
8. Try to close the ResultSet and Statement before reusing those.
9. If we use stmt = con.prepareStatement(sql query) inside loop, we should close it in the loop.
10. Try to close ResultSet, Statement, PreparedStatement and Connection in finally block.
thumb_up 1 thumb_down 0 flag 0
Tools use to manage software product life cycle :
1. Digite - Digite Enterprise (For Enterprise Businesses) – Solution incorporates a range of tools, content and processes to successfully convert business requirements to IT solutions
2. UGS PLM Solutions - TeamCenter (For Enterprise Businesses) – Integrated software solution designed to close the gap between idea capture and comprehensive product lifecycle management
3. Mystic Management Systems - ensurPLM (For All Businesses) – Tool for effectively managing the development of products from concept to design, through production planning and marketing
4. iRise - iRise Studio (For Enterprise Businesses) – Easy-to- use application definition solution used by business experts to quickly assemble functionally rich simulations of Web-based applications
5. PTC - Pro/ENGINEER Wildfire (For Enterprise Businesses) – Allows you to design faster than ever, while maximizing innovation and quality to ultimately create industry-winning products
thumb_up 1 thumb_down 0 flag 0
To deploy a Web Application:
- Arrange the resources (servlets, JSPs, static files, and deployment descriptors) in the prescribed directory format.
- Write the Web Application deployment descriptor (web.xml). In this step you register servlets, define servlet initialization parameters, register JSP tag libraries, define security constraints, and define other Web Application parameters. (Information on the various components of Web Applications is included throughout this document.)
For detailed instructions, see Writing the Web Application Deployment Descriptor.
- Create the WebLogic-Specific Deployment Descriptor (weblogic.xml). In this step you define JSP properties, JNDI mappings, security role mappings, and HTTP session parameters. If you do not need to define any of the attributes defined in this file, you do not need to create the file.
For detailed instructions on creating the WebLogic-specific deployment descriptor, see "Writing the WebLogic-Specific Deployment Descriptor".
- Archive the files in the above directory structure into a .war file. Only use archiving when the Web Application is ready for deployment in a production environment. (During development you may find it more convenient to update individual components of your Web Application by developing your application in exploded directory format.) To create a .war archive, use this command line from the root directory containing your Web Application:
jar cv0f myWebApp.war .
This command creates a Web Application archive file called myWebApp.war.
- Deploy the Web Application on Weblogic Server in one of two ways: using the Administration Console or by copying the Web Application into the applications directory of your domain.
To deploy a Web Application in archived war format using the Administration Console (you cannot deploy a Web Application in exploded directory format using this procedure):
- Select the Web Applications node in the left pane.
- Click Install a New Web Application.
- Browse to the location in your file system of the .war file.
- Click Upload.
This procedure creates a new entry in the config.xml file containing the configuration for your Web Application and copies your Web Application to an internal location.
To deploy a Web Application (in either archived or exploded format) by copying:
- Copy a .war file or the top-level directory containing a Web Application in exploded directory format into the mydomain/config/applications directory of your WebLogic Server distribution. (Where mydomain is the name of your domain.) As soon as the copy is complete, WebLogic Server automatically deploys the Web Application.
- (optional) Use the Administration Console to configure the Web Application. Once you change any attributes (see step 6., below) for the Web Application, the configuration is written to the config.xml file and the Web Application will be statically deployed the next time you restart WebLogic Server. If you do not use the Administration Console, your Web Application is still deployed automatically every time you start WebLogic Server, even though configuration information has not been saved to the config.xml file.
Note: If you deploy your Web Application in expanded form, read Modifying Components of a Web Application.
Note:If you modify any component of a .war file in its original location in your file system, you must redeploy your.war file by uploading it again from the Administration Console.
- Assign deployment attributes for your Web Application:
- Open the Administration Console
- Select the Web Applications node.
- Select your Web Application.
- Assign your Web Application to a WebLogic Server, cluster, or Virtual Host.
- Select the File tab and define the appropriate attributes.
thumb_up 1 thumb_down 0 flag 0
A three-way handshake is primarily used to create a TCP socket connection. It works when:
- A client node sends a SYN data packet over an IP network to a server on the same or an external network. The objective of this packet is to ask/infer if the server is open for new connections.
- The target server must have open ports that can accept and initiate new connections. When the server receives the SYN packet from the client node, it responds and returns a confirmation receipt – the ACK packet or SYN/ACK packet.
- The client node receives the SYN/ACK from the server and responds with an ACK packet.
Upon completion of this process, the connection is created and the host and server can communicate.
Alice ---> Bob SYNchronize with my Initial Sequence Number of X Alice <--- Bob I received your syn, I ACKnowledge that I am ready for [X+1] Alice <--- Bob SYNchronize with my Initial Sequence Number of Y Alice ---> Bob I received your syn, I ACKnowledge that I am ready for [Y+1] Notice, four events are occurring:
- Alice picks an ISN andSYNchronizes it with Bob.
- BobACKnowledges the ISN.
- Bob picks an ISN andSYNchronizes it with Alice.
- AliceACKnowledges the ISN.
thumb_up 1 thumb_down 0 flag 0
Deadlock is a permanent blocking of a set of threads that are competing for a set of resources. Just because some thread can make progress does not mean that a deadlock has not occurred somewhere else.
The most common error that causes deadlock isself deadlock orrecursive deadlock. In a self deadlock or recursive deadlock, a thread tries to acquire a lock already held by the thread. Recursive deadlock is very easy to program by mistake.
An example of deadlock is when two threads, thread 1 and thread 2, acquire a mutex lock, A and B, respectively. Suppose that thread 1 tries to acquire mutex lock B and thread 2 tries to acquire mutex lock A. Thread 1 cannot proceed while blocked waiting for mutex lock B. Thread 2 cannot proceed while blocked waiting for mutex lock A. Nothing can change. So, this condition is a permanent blocking of the threads, and a deadlock.
This kind of deadlock is avoided by establishing an order in which locks are acquired, alock hierarchy. When all threads always acquire locks in the specified order, this deadlock is avoided.
- The general idea behind deadlock avoidance is to prevent deadlocks from ever happening, by preventing at least one of the aforementioned conditions.
- This requires more information about each process, AND tends to lead to low device utilization. ( i.e. it is a conservative approach. )
- In some algorithms the scheduler only needs to know themaximum number of each resource that a process might potentially use. In more complex algorithms the scheduler can also take advantage of theschedule of exactly what resources may be needed in what order.
- When a scheduler sees that starting a process or granting resource requests may lead to future deadlocks, then that process is just not started or the request is not granted.
- A resource allocation state is defined by the number of available and allocated resources, and the maximum requirements of all processes in the system.
thumb_up 2 thumb_down 0 flag 0
AsyncTask is one of the easiest ways to implement parallelism in Android without having to deal with more complex methods like Threads. Though it offers a basic level of parallelism with the UI thread, it should not be used for longer operations (of, say, not more than 2 seconds).
AsyncTask has four methods do the task
-
onPreExecute() -
doInBackground() -
onProgressUpdate() -
onPostExecute()
wheredoInBackground() is the most important as it is where background computations are performed.
Code:
Here is a skeletal code outline with explanations:
public class AsyncTaskTestActivity extends Activity { @Override public void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.main); // This starts the AsyncTask // Doesn't need to be in onCreate() new MyTask().execute("my string paramater"); } // Here is the AsyncTask class: // // AsyncTask<Params, Progress, Result>. // Params – the type (Object/primitive) you pass to the AsyncTask from .execute() // Progress – the type that gets passed to onProgressUpdate() // Result – the type returns from doInBackground() // Any of them can be String, Integer, Void, etc. private class MyTask extends AsyncTask<String, Integer, String> { // Runs in UI before background thread is called @Override protected void onPreExecute() { super.onPreExecute(); // Do something like display a progress bar } // This is run in a background thread @Override protected String doInBackground(String... params) { // get the string from params, which is an array String myString = params[0]; // Do something that takes a long time, for example: for (int i = 0; i <= 100; i++) { // Do things // Call this to update your progress publishProgress(i); } return "this string is passed to onPostExecute"; } // This is called from background thread but runs in UI @Override protected void onProgressUpdate(Integer... values) { super.onProgressUpdate(values); // Do things like update the progress bar } // This runs in UI when background thread finishes @Override protected void onPostExecute(String result) { super.onPostExecute(result); // Do things like hide the progress bar or change a TextView } } } thumb_up 0 thumb_down 0 flag 0
The send, receive, and reply operations may be synchronous or asynchronous. A synchronous operation blocks a process till the operation completes. An asynchronous operation is non-blocking and only initiates the operation. The caller could discover completion by some other mechanism.
The notion of synchronous operations requires an understanding of what it means for an operation to complete. In the case of remote assignment, both the send and receive complete when the message has been delivered to the receiver. In the case of remote procedure call, the send, receive, and reply complete when the result has been delivered to the sender, assuming there is a return value. Otherwise, the send and receive complete when the procedure finishes execution.
Synchronous (one thread):
1 thread -> |<---A---->||<----B---------->||<------C----->| Synchronous (multi-threaded):
thread A -> |<---A---->| \ thread B ------------> ->|<----B---------->| \ thread C ----------------------------------> ->|<------C----->| thumb_up 2 thumb_down 0 flag 0
A Web server is a program that uses HTTP (Hypertext Transfer Protocol) to serve the files that form Web pages to users, in response to their requests, which are forwarded by their computers' HTTP clients. Dedicated computers and appliances may be referred to as Web servers as well.
Web Server Working
Web server respond to the client request in either of the following two ways:
-
Sending the file to the client associated with the requested URL.
-
Generating response by invoking a script and communicating with database
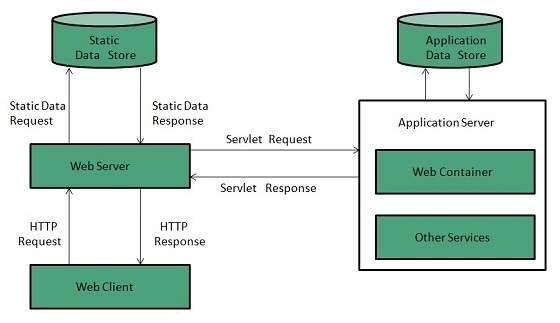
Key Points
-
When client sends request for a web page, the web server search for the requested page if requested page is found then it will send it to client with an HTTP response.
-
If the requested web page is not found, web server will the send anHTTP response:Error 404 Not found.
-
If client has requested for some other resources then the web server will contact to the application server and data store to construct the HTTP response.
thumb_up 3 thumb_down 0 flag 0
Virtual memory allows us to use a portion of our hard drive as though it were RAM and combine this part and the real RAM together. When the RAM runs low, virtual memory will move the data out of the RAM then transfer them into a space called paging file. In this way, the computing performance can be improved to some extent.
Generally speaking, the larger capacity RAM has, the faster programs run. Creating virtual memory truly is helpful to the computational speed when the RAM runs out, but not as helpful as extending RAM because the reading speed of RAM is much faster than HDD.
It seems that there's no need for us to use virtual memory anymore if we have a RAM that is large enough, not to mention that the reading speed of hard drive is way slower than it of RAM. Then will the running speed be improved if we disable the virtual memory? In fact, the answer is NO.
As a matter of fact, many of the core functions of Windows and some third-party software will employ paging files. In this case, third-party software may experience the lack of virtual memory if we choose to disable the latter, especially for the software like PhotoShop. Therefore, no matter how large the capacity of RAM is, it's still necessary for us to enable the virtual memory.
Another thing about virtual memory is that Windows only uses paging files when it's necessary. In other words, Windows does not use paging files all the time. So even though we disable virtual memory, the performance of our computer still won't be improved at all.
thumb_up 2 thumb_down 0 flag 0
Transmission Control Protocol (TCP) uses a sliding window for flow control.
The TCP sliding window determines the number of unacknowledged bytes, x, that one system can send to another. Two factors determine the value of x:
- The size of the send buffer on the sending system
- The size and available space in the receive buffer on the receiving system
The sending system cannot send more bytes than space that is available in the receive buffer on the receiving system. TCP on the sending system must wait to send more data until all bytes in the current send buffer are acknowledged by TCP on the receiving system.
On the receiving system, TCP stores received data in a receive buffer. TCP acknowledges receipt of the data, and advertises (communicates) a new receive window to the sending system. The receive window represents the number of bytes that are available in the receive buffer. If the receive buffer is full, the receiving system advertises a receive window size of zero, and the sending system must wait to send more data. After the receiving application retrieves data from the receive buffer, the receiving system can then advertise a receive window size that is equal to the amount of data that was read. Then, TCP on the sending system can resume sending data.
The available space in the receive buffer depends on how quickly data is read from the buffer by the receiving application. TCP keeps the data in its receive buffer until the receiving application reads it from that buffer. After the receiving application reads the data, that space in the buffer is available for new data. The amount of free space in the buffer is advertised to the sending system, as described in the previous paragraph.
Ensure that you understand the TCP window size when you use sliding window for flow control. The window size is the amount of data that can be managed. You might need to adjust the window size if the receive buffer receives more data than it can communicate.
How the send and receive buffers interact has the following consequences:
- The maximum number of unacknowledged bytes that a system can send is the smaller of two numbers:
- The send buffer size on the sending system
- The receive window size that the receiving system advertises to the sending system
- When the receiving application reads data as fast as the sending system can send it, the receive window stays at or near the size of the receive buffer. The result is that data flows smoothly across the network. If the receiving application can read the data fast enough, a larger receive window can improve performance.
- When the receive buffer is full, the receiving system advertises a receive window size of zero. The sending system must pause and temporarily cannot send any more data.
- In general, more frequent occurrences of zero size for the receive window results in overall slower data transmission across the network. Every time the receive window is zero, the sending system must wait before sending more data.
Typically, you set the send window and the receive window sizes separately for an operating system.
Reference : https://www.ibm.com/support/knowledgecenter/en/SSGSG7_7.1.0/com.ibm.itsm.perf.doc/c_network_sliding_window.html
thumb_up 5 thumb_down 0 flag 0
Locking mechanisms are a way for databases to produce sequential data output without the sequential steps. The locks provide a method for securing the data that is being used so no anomalies can occur like lost data or additional data that can be added because of the loss of a transaction.
Problems that Locks Solve
1. Lost Update Problem- An update can get lost if two or more transactions try to update the same data. The two transactions are unaware of each other, and data can be overwritten.
2. Temporary Update Problem - If one transaction updates the database and then fails, another transaction can read the incorrect value which lowers the integrity of the database.
3. Incorrect Summary Problem - If one transaction is calculating an aggregate while another transaction is updating the same data the integrity would be compromised.
4. Phantom Reads- When an insert or delete is performed on a row that is being used by another transaction the integrity of the data is compromised.
Different Types of Locks : There are three primary types of locks that are used in a database.
a) Read Locks- These types of locks make it so that data can only be read. Depending on the database system and restrictions on the read lock, this can make it so only one user can read the data to allowing every user access to reading the data but not being able to modify anything. The read lock can be applied to a single row, a section of rows, or an entire table. This can also be dependent on the type of database system that is being used that could limit the amount of data that can be locked for reading.
b) Write Locks- This type of lock is used for updates in the database system. When this lock is applied it prevents any other transactions from changing the records that are being accessed. This does allow transactions to read the data before it is modified and the changes are made permanent.
c) Exclusive Write Locks- This type of lock is similar to a write lock. The only difference is that with an exclusive write lock, the only things that can look at the data or modify the data is the original transaction. No other transaction can read the data while this lock is applied. There are also many other locks that signal intention to request another type of lock. These locks are called multi-level-locks. This is useful to show other transactions what types of locks the transaction has throughout the hierarchy of data levels.
d) Multi-Level-LocksUpdate Lock- Signals intention to request an exclusive lock in the near future.
e) IS Lock- Signals intent to request shared (read) lock in the near future.
f) IX Lock- Signals intent to request an exclusive (write) lock in the near future.
g) Two-Phase Locking Protocol The Two Phase Commit is designed to coordinate the transactions of the requests to the system. The idea behind the protocol is to produce serialized results from a non-serialized system. This protocol requires that each transaction issues lock and unlock requests in two phases: the shrinking phase and the growing phase. During the growing phase transactions may obtain locks, but cannot release any. During the shrinking phase transactions may release locks but may not obtain any new locks. By following this protocol any update problems with the transaction can be detected and one transaction gets rolled back. It also can raise the priority of the affected transaction to prevent a repeat of the problem.
thumb_up 0 thumb_down 0 flag 0
The most crucial structure for recovery operations is the redo log, which consists of two or more preallocated files that store all changes made to the database as they occur. Every instance of an Oracle Database has an associated redo log to protect the database in case of an instance failure.
Redo Log Contents
Redo log files are filled with redo records. A redo record, also called a redo entry, is made up of a group of change vectors, each of which is a description of a change made to a single block in the database. For example, if you change a salary value in an employee table, you generate a redo record containing change vectors that describe changes to the data segment block for the table, the undo segment data block, and the transaction table of the undo segments.
Redo entries record data that you can use to reconstruct all changes made to the database, including the undo segments. Therefore, the redo log also protects rollback data. When you recover the database using redo data, the database reads the change vectors in the redo records and applies the changes to the relevant blocks.
For further reading, please refer : https://docs.oracle.com/cd/B28359_01/server.111/b28310/onlineredo001.htm#ADMIN11304
thumb_up 4 thumb_down 0 flag 0
The load factor is a measure of how full the array list is allowed to get before its capacity is automatically increased.
ForArrayList, every time you put an element into it, it will check if the nested array needs to be enlarge its size. If yes, generally, its size will grow with:
newCapacity = oldCapacity + (oldCapacity >> 1); For some special case, for example, add many or huge number of elements, things will be different. Please refergrow(int minCapacity) function injava.util.ArrayList source code.
TheArrayList is simple growing array. When trying to add element, and the buffer size is exceeded, it is simply growing. So the initial size can be any positive value.
The 1 would be too little. Even with a few elements we will have a few resize operations. The 100 would be a loss of space. So, 10 is kept as default capacity of ArrayList.
thumb_up 2 thumb_down 0 flag 0
A translation lookaside buffer (TLB) is a memory cache that stores recent translations of virtual memory to physical addresses for faster retrieval.
- When a virtual memory address is referenced by a program, the search starts in the CPU. First, instruction caches are checked. If the required memory is not in these very fast caches, the system has to look up the memory's physical address. At this point, TLB is checked for a quick reference to the location in physical memory.
- When an address is searched in the TLB and not found, the physical memory must be searched with a memory page crawl operation. As virtual memory addresses are translated, values referenced are added to TLB. When a value can be retrieved from TLB, speed is enhanced because the memory address is stored in the TLB on processor. Most processors include TLBs to increase the speed of virtual memory operations through the inherent latency-reducing proximity as well as the high-running frequencies of current CPU's.
- TLB's also add the support required for multi-user computers to keep memory separate, by having a user and a supervisor mode as well as using permissions on read and write bits to enable sharing.
- TLB's can suffer performance issues from multitasking and code errors. This performance degradation is called a cache thrash. Cache thrash is caused by an ongoing computer activity that fails to progress due to excessive use of resources or conflicts in the caching system.
thumb_up 1 thumb_down 0 flag 0
Java ClassLoader loads a java class file into java virtual machine. It is as simple as that. It is not a huge complicated concept to learn and every java developer must know about the java class loaders and how it works.
Like NullPointerException, one exception that is very popular is ClassNotFoundException. Java class loader is the culprit that is causing this exception.
Types (Hierarchy) of Java Class Loaders
Java class loaders can be broadly classified into below categories:
- Bootstrap Class Loader
Bootstrap class loader loads java's core classes like java.lang, java.util etc. The Bootstrap class loader loads key Java classes. Bootstrap class loader loads the basic classes from Java library, like java.*, javax.*. This is the root in the class loader hierarchy.These are classes that are part of java runtime environment. Bootstrap class loader is native implementation and so they may differ across different JVMs.
- Extensions Class Loader
JAVA_HOME/jre/lib/ext contains jar packages that are extensions of standard core java classes. Extensions class loader loads classes from this ext folder. Using the system environment property java.ext.dirs you can add 'ext' folders and jar files to be loaded using extensions class loader. The Extension class loader loads the classes from the JRE's extension directories, such lib/ext directories
- System Class Loader
The System class loader loads the classes from the system class path, which are set by the CLASSPATH environment variable.
thumb_up 3 thumb_down 0 flag 0
HashTable
-
Hashtableis an implementation of Map data structure - This is a legacy class in which all methods are synchronized on Hashtable instances usingsynchronizedkeyword.
- Thread-safe as it's method are synchronized
ConcurrentHashMap
-
ConcurrentHashMapimplements Map data structure and also provide thread safety like Hashtable. - It works by dividing complete hashtable array in to segments or portions and allowing parallel access to those segments.
- The locking is at a much finer granularity at a hashmap bucket level.
- Use
ConcurrentHashMapwhen you need very high concurrency in your application. - It is thread-safe without synchronizing the whole map.
- Reads can happen very fast while write is done with a lock on segment level or bucket level.
- There is no locking at the object level.
-
ConcurrentHashMapdoesn't throw aConcurrentModificationExceptionif one thread tries to modify it while another is iterating over it. -
ConcurrentHashMapdoes not allow NULL values, so key can not be null inConcurrentHashMap -
ConcurrentHashMapdoesn't throw aConcurrentModificationExceptionif one thread tries to modify it, while another is iterating over it.

thumb_up 0 thumb_down 0 flag 0
This method compares this String to another String, ignoring case considerations. Two strings are considered equal ignoring case, if they are of the same length, and corresponding characters in the two strings are equal ignoring case.
Syntax
Here is the syntax of this method − public boolean equalsIgnoreCase(String anotherString) Parameters
Here is the detail of parameters −
-
anotherString − the String to compare this String against.
Return Value
-
This method returns true if the argument is not null and the Strings are equal, ignoring case; false otherwise.
Example
public class Test { public static void main(String args[]) { String Str1 = new String("This is really not immutable!!"); String Str2 = Str1; String Str3 = new String("This is really not immutable!!"); String Str4 = new String("This IS REALLY NOT IMMUTABLE!!"); boolean retVal; retVal = Str1.equals( Str2 ); System.out.println("Returned Value = " + retVal ); retVal = Str1.equals( Str3 ); System.out.println("Returned Value = " + retVal ); retVal = Str1.equalsIgnoreCase( Str4 ); System.out.println("Returned Value = " + retVal ); } } This will produce the following result −
Output
Returned Value = true Returned Value = true Returned Value = true thumb_up 10 thumb_down 0 flag 0
To understand system calls, first one needs to understand the difference betweenkernel mode anduser mode of a CPU. Every modern operating system supports these two modes.

Modes supported by the operating system
Kernel Mode
- When CPU is inkernel mode, the code being executed can access any memory address and any hardware resource.
- Hence kernel mode is a very privileged and powerful mode.
- If a program crashes in kernel mode, the entire system will be halted.
User Mode
- When CPU is inuser mode, the programs don't have direct access to memory and hardware resources.
- In user mode, if any program crashes, only that particular program is halted.
- That means the system will be in a safe state even if a program in user mode crashes.
- Hence, most programs in an OS run in user mode.
System Call
When a program in user mode requires access to RAM or a hardware resource, it must ask the kernel to provide access to that resource. This is done via something called asystem call.
When a program makes a system call, the mode is switched from user mode to kernel mode. This is called acontext switch.
Then the kernel provides the resource which the program requested. After that, another context switch happens which results in change of mode from kernel mode back to user mode.
Generally, system calls are made by the user level programs in the following situations:
- Creating, opening, closing and deleting files in the file system.
- Creating and managing new processes.
- Creating a connection in the network, sending and receiving packets.
- Requesting access to a hardware device, like a mouse or a printer.
thumb_up 3 thumb_down 0 flag 0
Pen drives are an external and portable media and smaller in size and is made up of chip, It is also known as flash drive.

thumb_up 2 thumb_down 0 flag 0
Interrupt is a signal which has highest priority from hardware or software which processor should process its signal immediately.
Types of Interrupts:
Although interrupts have highest priority than other signals, there are many type of interrupts but basic type of interrupts are
- Hardware Interrupts: If the signal for the processor is from external device or hardware is called hardware interrupts. Example: from keyboard we will press the key to do some action this pressing of key in keyboard will generate a signal which is given to the processor to do action, such interrupts are called hardware interrupts. Hardware interrupts can be classified into two types they are
- Maskable Interrupt: The hardware interrupts which can be delayed when a much highest priority interrupt has occurred to the processor.
- Non Maskable Interrupt: The hardware which cannot be delayed and should process by the processor immediately.
- Software Interrupts: Software interrupt can also divided in to two types. They are
- Normal Interrupts: the interrupts which are caused by the software instructions are called software instructions.
- Exception: unplanned interrupts while executing a program is called Exception. For example: while executing a program if we got a value which should be divided by zero is called a exception.
Classification of Interrupts According to Periodicity of Occurrence:
- Periodic Interrupt: If the interrupts occurred at fixed interval in timeline then that interrupts are called periodic interrupts
- Aperiodic Interrupt: If the occurrence of interrupt cannot be predicted then that interrupt is called aperiodic interrupt.
Classification of Interrupts According to the Temporal Relationship with System Clock:
- Synchronous Interrupt: The source of interrupt is in phase to the system clock is called synchronous interrupt. In other words interrupts which are dependent on the system clock. Example: timer service that uses the system clock.
- Asynchronous Interrupts: If the interrupts are independent or not in phase to the system clock is called asynchronous interrupt.
thumb_up 3 thumb_down 0 flag 0
The major types of routing protocols :
- Routing Information Protocols(RIP)
- Interior Gateway Protocol (IGRP)
- Open Shortest Path First (OSPF)
- Exterior Gateway Protocol (EGP)
- Enhanced interior gateway routing protocol (EIGRP)
- Border Gateway Protocol (BGP)
- Intermediate System-to-Intermediate System (IS-IS)
Routing information protocols (RIP)
RIP (Routing Information Protocol) is a forceful protocol type used in local area network and wide area network. RIP (Routing Information Protocol) type is categorized interior gateway protocol within the use of distance vector algorithm. Routing information protocols defined in 1988. It also has version 2 and nowadays both versions are in use. Technically it is outdated by more sophisticated techniques such as (OSPF) and the OSI protocol IS-IS.
Interior gateway routing protocol (IGRP)
It is distance vector IGRP (Interior gateway Protocol) make-believe by Cisco. Router used it to exchange routing data within an independent system. Interior gateway routing protocol created in part to defeat the confines of RIP (Routing Information Protocol) in large networks. It maintains multiple metrics for each route as well as reliability, MTU, delay load, and bandwidth. The maximum hop of EIGRP is 255 and routing updates are transmitting 90 seconds. It measured in classful routing protocol, but it is less popular because of wasteful of IP address space.
Open shortest path first (OSPF)
Open Shortest Path First (OSPF) is an active routing protocol used in internet protocol. Particularly it is a link state routing protocol and includes into the group of interior gateway protocol. Open Shortest Path First (OSPF) operating inside a distinct autonomous system. The version 2 of Open Shortest Path First (OSPF) defined in 1998 for IPv4 then the OSPF version 3 in RFC 5340 in 2008. The Open Shortest Path First (OSPF) most widely used in the network of big business companies.
Exterior Gateway Protocol (EGP)
The absolute routing protocol for internet is exterior gateway protocol which is specified in 1982 by Eric C. EGP (Exterior Gateway Protocol) initially expressed in RFC827 and properly specified in RFC 904 in 1984.The Exterior Gateway Protocol (EGP) is unlike distance vector and path vector protocol. It is a topology just like tree.
Enhanced interior gateway routing protocol (EIGRP)
Enhanced Interior Gateway Routing Protocol (EIGRP) based on their original IGRP while it is a Cisco proprietary routing protocol. It is a distance-vector routing protocol in advance within the optimization to lessen both the routing unsteadiness incurred after topology alteration, plus the use of bandwidth and processing power in the router which support enhanced interior gateway routing protocol will automatically reallocate route information to IGRP (Enhanced Interior Gateway Routing Protocol) neighbors by exchanging the 32 bit EIGRP (Enhanced Interior Gateway Routing Protocol) metric to the 24 bit IGRP metric. Generally optimization based on DUAL work from SRI which assured loop free operation and offer a means for speedy junction.
Border Gateway Protocol (BGP)
Border Gateway Protocol (BGP) are the core routing protocol of the internet and responsible to maintain a table of Internet protocol networks which authorize network reaching capability between AS. The Border Gateway Protocol (BGP) expressed as path vector protocol. It doesn't employ conventional IGP metrics but making routing judgment based on path, network policies. It is created to replace the Exterior Gateway Protocol (EGP) routing protocol to permit completely decentralized routing in order to permit the removal of the NSF Net which consent to internet to turn into a truly decentralized system. The fourth version of Border Gateway Protocol (BGP)has been in use since 1994 and 4th version from 2006 .The 4 version RFC 4271 has many features such as it correct a lots of previous errors, illuminating vagueness and brought t the RFC much nearer to industry practice.
Intermediate System-to-Intermediate System (IS-IS)
Intermediate System-to-Intermediate System (IS-IS)is a great protocol used by network devices to determine the best way to promoted datagram from side to side a packet switched network and this process is called routing. It was defined in ISO/IEC 10589 2002 within the OSI reference design. Intermediate system-to-intermediate system (IS-IS) differentiate among levels such as level 1and level 2. The routing protocol can be changed without contacting the intra area routing protocol.
thumb_up 4 thumb_down 6 flag 3
Aspin-lock is usually used when there is low contention for the resource and the CPU will therefore only make a few iterations before it can move on to do productive work. The regular lock is used if the resource cannot be acquired in a reasonable time-frame. This is done to reduce the overhead with context switches in settings where locks usually are quickly obtained.
Spin locks perform a busy wait - i.e. it keeps running loop:
while (try_acquire_resource ()); ... release(); It performs very lightweight locking/unlocking but if the locking thread will be preempted by other which will try to access the same resource the second one will simply try to acquire resource until it run out of it CPU quanta.
On the other hand mutex behave more like:
if (!try_lock()) { add_to_waiting_queue (); wait(); } ... process *p = get_next_process_from_waiting_queue (); p->wakeUp (); Hence if the thread will try to acquire blocked resource it will be suspended till it will be availed for it. Locking/unlocking is much more heavy but the waiting is 'free' and 'fair'.
Semaphore is a lock that is allowed to be used multiple (known from initialization) number of times - for example 3 threads are allowed to simultaneously hold the resource but no more. It is used for example in producer/consumer problem or in general in queues:
P(resources_sem) resource = resources.pop() ... resources.push(resources) V(resources_sem) thumb_up 7 thumb_down 1 flag 0
OSPF (Open Shortest Path First) is a router protocol used to find the best path for packets as they pass through a set of connected networks. OSPF is designated by the Internet Engineering Task Force (IETF) as one of several Interior Gateway Protocols (IGPs) -- that is, protocols aimed at traffic moving around within a larger autonomous system network like a single enterprise's network, which may in turn be made up of many separate local area networks linked through routers.
Using OSPF, a router that learns of a change to a routing table (when it is reconfigured by network staff, for example) or detects a change in the network immediately multi casts the information to all other OSPF hosts in the network so they will all have the same routing table information. Unlike RIP, which requires routers to send the entire routing table to neighbors every 30 seconds, OSPF sends only the part that has changed and only when a change has taken place. When routes change -- sometimes due to equipment failure -- the time it takes OSPF routers to find a new path between endpoints with no loops (which is called "open") and that minimizes the length of the path is called the convergence time.
Although it is intended to replace RIP, OSPF has RIP support built in both for router-to-host communication and for compatibility with older networks using RIP as their primary protocol.
thumb_up 2 thumb_down 0 flag 0
- Spanning Tree Protocol (STP) was developed to prevent the broadcast storms caused by switching loops. STP was originally defined in IEEE 802.1D.
- Switches running STP will build a map or topology of the entire switching network. STP will identify if there are any loops, and then disable or block as many ports as necessary to eliminate all loops in the topology.
- A blocked port can be reactivated if another port goes down. This allows STP to maintain redundancy and fault-tolerance.
- However, because ports are blocked to eliminate loops, STP does not support load balancing unless an EtherChannel is used. EtherChannel is covered in great detail in another guide.
- Building the STP topology is a multistep convergence process:
- A Root Bridge is elected
- Root ports are identified
- Designated ports are identified
- Ports are placed in a blocking state as required, to eliminate loops
The Root Bridge serves as the central reference point for the STP topology. Once the full topology is determined, and loops are eliminated, the switches are considered converged. STP is enabled by default on all Cisco switches, for all VLANs.
For further detailed reading : http://www.routeralley.com/guides/stp.pdf
thumb_up 4 thumb_down 0 flag 0
Static Memory Allocation:
Memory is allocated for the declared variable by the compiler. The address can be obtained by using 'address of' operator and can be assigned to a pointer. The memory is allocated during compile time. Since most of the declared variables have static memory, this kind of assigning the address of a variable to a pointer is known as static memory allocation.
Dynamic Memory Allocation:
Allocation of memory at the time of execution (run time) is known as dynamic memory allocation. The functions calloc() and malloc() support allocating of dynamic memory. Dynamic allocation of memory space is done by using these functions when value is returned by functions and assigned to pointer variables.
It is sometimes also referred to as 'heap' memory, although it has nothing to do with the heap data-structure.
int * a = malloc(sizeof(int)); Use of dynamic memory allocation over static are :
- Memory is allocated during the execution of the program.
- Memory Bindings are established and destroyed during the Execution.
- Allocated only when program unit is active.
- Less Memory space required.
thumb_up 2 thumb_down 0 flag 0
Maximum Salary in each department :
SELECT deptId, MAX(Salary) FROM Employee GROUP BY deptId thumb_up 0 thumb_down 0 flag 0
N maximum salary:
SELECT MAX(EmpSalary) FROM Salary WHERE EmpSalary IN(SELECT TOP N EmpSalary FROM Salary ORDER BY EmpSalary ASC) for Ex: 3 maximum salary:
SELECT MAX(EmpSalary) FROM Salary WHERE EmpSalary IN(SELECT TOP 3 EmpSalary FROM Salary ORDER BY EmpSalary ASC) thumb_up 4 thumb_down 0 flag 0
Constant Pointers
Lets first understand what a constant pointer is. A constant pointer is a pointer that cannot change the address its holding. In other words, we can say that once a constant pointer points to a variable then it cannot point to any other variable.
A constant pointer is declared as follows :
<type of pointer> * const <name of pointer> An example declaration would look like :
int * const ptr; Lets take a small code to illustrate these type of pointers :
#include<stdio.h> int main(void) { int var1 = 0, var2 = 0; int *const ptr = &var1; ptr = &var2; printf("%d\n", *ptr); return 0; } In the above example :
- We declared two variables var1 and var2
- A constant pointer 'ptr' was declared and made to point var1
- Next, ptr is made to point var2.
- Finally, we try to print the value ptr is pointing to.
So, in a nutshell, we assigned an address to a constant pointer and then tried to change the address by assigning the address of some other variable to the same constant pointer.
Pointer to Constant
As evident from the name, a pointer through which one cannot change the value of variable it points is known as a pointer to constant. These type of pointers can change the address they point to but cannot change the value kept at those address.
A pointer to constant is defined as :
const <type of pointer>* <name of pointer> An example of definition could be :
const int* ptr; Lets take a small code to illustrate a pointer to a constant :
#include<stdio.h> int main(void) { int var1 = 0; const int* ptr = &var1; *ptr = 1; printf("%d\n", *ptr); return 0; } In the code above :
- We defined a variable var1 with value 0
- we defined a pointer to a constant which points to variable var1
- Now, through this pointer we tried to change the value of var1
- Used printf to print the new value.
thumb_up 2 thumb_down 2 flag 0

* = Primary Key in every table.
thumb_up 0 thumb_down 0 flag 0
Converting an expression of a given type into another type is known astype-casting. Some ways to type cast are :
1. Implicit conversion
Implicit conversions do not require any operator. They are automatically performed when a value is copied to a compatible type. For example:
short a=2000; int b; b=a; Here, the value of a has been promoted from short to int and we have not had to specify any type-casting operator. This is known as a standard conversion. Standard conversions affect fundamental data types, and allow conversions such as the conversions between numerical types (short to int, int to float, double to int...), to or from bool, and some pointer conversions. Some of these conversions may imply a loss of precision, which the compiler can signal with a warning. This warning can be avoided with an explicit conversion.
Implicit conversions also include constructor or operator conversions, which affect classes that include specific constructors or operator functions to perform conversions. For example:
class A {}; class B { public: B (A a) {} }; A a; B b=a; Here, an implicit conversion happened between objects of class A and class B, because B has a constructor that takes an object of class A as parameter. Therefore implicit conversions from A to B are allowed.
2. Explicit conversion
C++ is a strong-typed language. Many conversions, specially those that imply a different interpretation of the value, require an explicit conversion. We have already seen two notations for explicit type conversion: functional and c-like casting:
short a=2000; int b; b = (int) a; // c-like cast notation b = int (a); // functional notation In order to control these types of conversions between classes, we have four specific casting operators: dynamic_cast, reinterpret_cast, static_cast and const_cast. Their format is to follow the new type enclosed between angle-brackets (<>) and immediately after, the expression to be converted between parentheses.
dynamic_cast <new_type> (expression)
reinterpret_cast <new_type> (expression)
static_cast <new_type> (expression)
const_cast <new_type> (expression)
Further details about these casts for classes can be referred from : http://www.cplusplus.com/doc/oldtutorial/typecasting/
thumb_up 2 thumb_down 0 flag 0
The DELETE Statement is used to delete rows from a table.
Syntax of a SQL DELETE Statement
DELETE FROM table_name [WHERE condition]; table_name -- the table name which has to be updated. The "where" clause in the sql delete command is optional and it identifies the rows in the column that gets deleted. If you do not include the WHERE clause all the rows in the table is deleted, so be careful while writing a DELETE query without WHERE clause.
SQL DELETE Example
To delete an employee with id 100 from the employee table, the sql delete query would be like, DELETE FROM employee WHERE id = 100; To delete all the rows from the employee table, the query would be like, DELETE FROM employee; SQL TRUNCATE Statement
The SQL TRUNCATE command is used to delete all the rows from the table and free the space containing the table.
Syntax to TRUNCATE a table:
TRUNCATE TABLE table_name; SQL TRUNCATE Statement Example
To delete all the rows from employee table, the query would be like, TRUNCATE TABLE employee; Difference between DELETE and TRUNCATE Statements:
DELETE Statement: This command deletes only the rows from the table based on the condition given in the where clause or deletes all the rows from the table if no condition is specified. But it does not free the space containing the table. After performing a DELETE operation you need to COMMIT or ROLLBACK the transaction to make the change permanent or to undo it. Note that this operation will cause all DELETE triggers on the table to fire.
TRUNCATE statement: This command is used to delete all the rows from the table and free the space containing the table. The operation cannot be rolled back and no triggers will be fired. As such, TRUNCATE is faster and doesn't use as much undo space as a DELETE.
Here are some reasons to use TRUNCATE:
- You want to "reset" a table to its empty state. All rows are removed, and identity key values reset to the initial defined values.
- You need to have a super quick way of clearing out table data. I can see this occurring when you need to repeatedly import test data or you have routines that use work tables or scratch tables to store information.
- You want to remove rows from a table without activating the table's after delete trigger.
Keep in mind that TRUNCATE will lock the table, so obviously don't use this command on a table being shared by many concurrent users.
Here are some things that happen during a DELETE that don't during the TRUNCATE:
- Any deletion triggers are executed on the affected table.
- You are allowed to DELETE records that have foreign key constraints defined. A TRUNCATE cannot be executed if these same constraints are in place.
- Record deletions don't reset identity keys. This is important when you need to guarantee each row uses a key that has never been used before. Perhaps, this need to happen for audit reasons.
- Depending on the locking you are using, row locks are placed on deleted rows. Unaffected rows remain unlocked.
thumb_up 0 thumb_down 0 flag 0
C program execution :
- For executing any program we type it in a text editor and save it by .c extension
- This .c extension file is the source file and input to the compiler which converts it to machine equivalent code.
- If there are no errors then .obj file is made which is input to linker to link library files
- and then the .exe file is generated
- if in gcc a.out is the default file created .
Java program execution :
- First of all we need Java Virtual machine by installing JDK(Java Development Kit) to execute any java program .
- When we compile any program with .java as source file it gets converted to .class file if there are no errors.
- This .class file consists of byte code which is input to JVM(interpreter).
- This file will only be made if there is any class in .java source file. In case of empty java file no .class file is created .The name of the .class file will be the name of the class in your source file.
- If there are multiple class in java files then corresponding to each class a .class file will be created.
The C programs get compiled in machine code i.1 0's and 1's but in case of Java it gets converted to byte code in .class file and hence is portable.
thumb_up 3 thumb_down 0 flag 0
1.
Mathematically
7 Minutes Sand Timer Finished.
Time Remaining in 11 minutes timer – 4 minutes
Reversing the 7 minutes timer – 4 minutes will elapse. 3 Minutes will left.
Once 11 minutes gets over reverse the 11 minutes timer again to use that 3 minutes. 8 Minutes left.
Now Reverse 7 minutes timer to measure 7+8 = 15 minutes.
2.
The sixth person took the basket too, leaving the sixth egg in it.
3.
Approach 1:
888 + 88 + 8 + 8 + 8
Approach 2:
(8(8(8+8)-(8+8)/8))-8
Approach 3:
(888-8) + 8×(8+8) - 8
((8×(8+8))-((8+8+8)/8))×8
((8×(8+8))-((88/8)-8))×8
(8888-888)/8
Approach 4:
8(8×8+8×8)-8-8-8
thumb_up 0 thumb_down 4 flag 0
1.

Squares: AFGC and BDGF
Triangles: AFE,ABD,DGE and DCA
2.
I set one stick to fire on both ends and the other stick on only end. I let the first stick burn completely which measures me 30 minutes. Then I put the other end of the burning second stick on fire and let it burn completely. Now the second stick takes 15 minutes to burn completely.
3.
I think this can be achieved in 2 steps.
Let us give name to each ball B1 B2 B3 B4 B5 B6 B7 B8 B9
Now we will divide all the balls into 3 groups.
Group1 - B1 B2 B3
Group2 - B4 B5 B6
Group3 - B7 B8 B9
Step1 - Now weigh any two groups. Let's assume we choose Group1 on left side of the scale and Group2 on the right side.
So now when we weigh these two groups we can get 3 outcomes.
- Weighing scale tilts on left - Group1 has a light ball.
- Weighing scale tilts on right - Group2 has a light ball.
- Weighing scale remains balanced - Group3 has a light ball.
Lets assume we got the outcome as 3. i.e Group 3 has a light ball.
Step2 - Now weigh any two balls from Group3. Lets assume we keep B7 on left side of the scale and B8 on right side.
So now when we weigh these two balls we can get 3 outcomes.
- Weighing scale tilts on left - B7 is the light ball.
- Weighing scale tilts on right - B8 is the light ball.
- Weighing scale remains balanced - B9 is the light ball.
4.
The ants can only avoid a collision if they all decide to move in the same direction (either clockwise or anti-clockwise). If the ants do not pick the same direction, there will definitely be a collision. Each ant has the option to either move clockwise or anti-clockwise. There is a one in two chance that an ant decides to pick a particular direction. Using simple probability calculations, we can determine the probability of no collision.
P(No collision) = P(All ants go in a clockwise direction) + P( All ants go in an anti-clockwise direction) = 0.5 * 0.5 * 0.5 + 0.5 * 0.5 * 0.5 =0.25
thumb_up 6 thumb_down 0 flag 0
The man committed suicide.
He stood on a big ice cube and hung himself. After some time the ice melted and water puddle only present in the scene along with the hung man.
thumb_up 4 thumb_down 0 flag 0
Yes, one can edit standard C libraries.
When should I edit
- Almost never. Even if you have a better implementation for a function, add it as a separate library or utility function in your project.
- If you are compiler/libc implementer, you need to edit libraries to fix the bugs or enhance features inside the scope of specs.
- Locally to study how do standard libraries work. Changing them for live project may give you many surprises.
There's something like Open/Closed Principle. Meaning, Software entities should be open to extend and closed for modifications. Most of the standard libraries help you to solve a wide majority of your programming problems. However, modifying them are not recommended. You may write your own, may be leveraging the features of standard C library. You can clone the entire source and write my-glorified-std-lib but it will no more be called "Standard C Library".
thumb_up 1 thumb_down 1 flag 0
A iterative model is a way to describe a SDLC as a sequence of consecutive steps.
A spiral model is a way to implement a iterative model, where each iteration follows a waterfall-like model. With each iteration, the product is updated, more features are added etc.

thumb_up 2 thumb_down 0 flag 0
Software Testing
Software testing is the process of evaluation a software item to detect differences between given input and expected output. Also to assess the feature of A software item. Testing assesses the quality of the product. Software testing is a process that should be done during the development process. In other words software testing is a verification and validation process.
1. Verification
Verification is the process to make sure the product satisfies the conditions imposed at the start of the development phase. In other words, to make sure the product behaves the way we want it to.
2. Validation
Validation is the process to make sure the product satisfies the specified requirements at the end of the development phase. In other words, to make sure the product is built as per customer requirements.
Basics of software testing
There are two basics of software testing: black box testing and white box testing.
Black box Testing
Black box testing is a testing technique that ignores the internal mechanism of the system and focuses on the output generated against any input and execution of the system. It is also called functional testing.
White box Testing
White box testing is a testing technique that takes into account the internal mechanism of a system. It is also called structural testing and glass box testing.
Black box testing is often used for validation and white box testing is often used for verification.
Types of testing
- Unit Testing
- Integration Testing
- Functional Testing
- System Testing
- Stress Testing
- Performance Testing
- Usability Testing
- Acceptance Testing
- Regression Testing
- Beta Testing
Unit Testing
Unit testing is the testing of an individual unit or group of related units. It falls under the class of white box testing. It is often done by the programmer to test that the unit he/she has implemented is producing expected output against given input.
Integration Testing
Integration testing is testing in which a group of components are combined to produce output. Also, the interaction between software and hardware is tested in integration testing if software and hardware components have any relation. It may fall under both white box testing and black box testing.
Functional Testing
Functional testing is the testing to ensure that the specified functionality required in the system requirements works. It falls under the class of black box testing.
System Testing
System testing is the testing to ensure that by putting the software in different environments (e.g., Operating Systems) it still works. System testing is done with full system implementation and environment. It falls under the class of black box testing.
Stress Testing
Stress testing is the testing to evaluate how system behaves under unfavorable conditions. Testing is conducted at beyond limits of the specifications. It falls under the class of black box testing.
Performance Testing
Performance testing is the testing to assess the speed and effectiveness of the system and to make sure it is generating results within a specified time as in performance requirements. It falls under the class of black box testing.
Usability Testing
Usability testing is performed to the perspective of the client, to evaluate how the GUI is user-friendly? How easily can the client learn? After learning how to use, how proficiently can the client perform? How pleasing is it to use its design? This falls under the class of black box testing.
Acceptance Testing
Acceptance testing is often done by the customer to ensure that the delivered product meets the requirements and works as the customer expected. It falls under the class of black box testing.
Regression Testing
Regression testing is the testing after modification of a system, component, or a group of related units to ensure that the modification is working correctly and is not damaging or imposing other modules to produce unexpected results. It falls under the class of black box testing.
Beta Testing
Beta testing is the testing which is done by end users, a team outside development, or publicly releasing full pre-version of the product which is known as beta version. The aim of beta testing is to cover unexpected errors. It falls under the class of black box testing.
thumb_up 0 thumb_down 0 flag 0
There are two basic syntaxes of the INSERT INTO statement which are shown below.
INSERT INTO TABLE_NAME (column1, column2, column3,...columnN) VALUES (value1, value2, value3,...valueN); Here, column1, column2, column3,...columnN are the names of the columns in the table into which you want to insert the data.
You may not need to specify the column(s) name in the SQL query if you are adding values for all the columns of the table. But make sure the order of the values is in the same order as the columns in the table.
TheSQL INSERT INTO syntax will be as follows −
INSERT INTO TABLE_NAME VALUES (value1,value2,value3,...valueN); Populate one table using another table
You can populate the data into a table through the select statement over another table; provided the other table has a set of fields, which are required to populate the first table.
Here is the syntax −
INSERT INTO first_table_name [(column1, column2, ... columnN)] SELECT column1, column2, ...columnN FROM second_table_name [WHERE condition]; thumb_up 10 thumb_down 0 flag 0
By definition, the putcommand replaces the previous value associated with the given key in the map (conceptually like an array indexing operation for primitive types).
The map simply drops its reference to the value. If nothing else holds a reference to the object, that object becomes eligible for garbage collection. Additionally, Java returns any previous value associated with the given key (ornull if none present), so you can determine what was there and maintain a reference if necessary. HashMap is aMap type. That means every time you add an entry, you add a key-value pair.
InHashMap you can have duplicate values, but not duplicate keys. InHashMap the new entry will replace the old one. The most recent entry will be in theHashMap.
In the case ofHashMap, it replaces the old value with the new one.
In the case ofHashSet, the item isn't inserted.
thumb_up 22 thumb_down 2 flag 1
Facebook uses the Graph data structure to maintain relationship between friends. In fb each user is considered as a vertex and if an edge connects two users(vertices) then those two users are considered as friends.
The concept of mutual friends is mainly finding the strongly connected components(SCC) in a graph.This can be done by Kosaraju's algo of finding SCC in a graph.
Consider a Graph where Nodes are people and you have different kinds of vertices:
- v1: The people N is friends with (undirected)
- v2: The people whose wall were visited by N (directed, weighted by visit number)
- v3: The people whose shared articles were seen by N (directed, weighted by article number)
- v4: The people who commented/liked/shared on N's any activity (directed, weighted by a formula based on the number of actions of different kinds)
- v5: The people mentioned in a post/comment of N (directed)
Indirect paths should be taken into account (friend of a friend), N is a Node. Based on the attributes of the graph the likelyness of the person is known can be computed by a formula, which can be defined in infinitely many ways. Also, one person might know another one, who forgot about the first one.
thumb_up 6 thumb_down 0 flag 0
You can use a trie :
- every node of the trie has all the children that begins with the value itself, for example: from"in" node you can visit the subtree of all strings starting with"in"
- in your case you have to consider score so you can first gather all children (traversing the tree) and then sort them according to the score or whatever
- if you really want to keepHamming Distance (edit-distance) you can adapt the trie to build children according to it
A trie is a data structure that can be used to quickly find words that match a prefix.
Here's a comparison of 3 different auto-complete implementations (though it's in Java not C++).
* In-Memory Trie * In-Memory Relational Database * Java Set When looking up keys, the trie is marginally faster than the Set implementation. Both the trie and the set are a good bit faster than the relational database solution.
The setup cost of the Set is lower than the Trie or DB solution. You'd have to decide whether you'd be constructing new "wordsets" frequently or whether lookup speed is the higher priority.
thumb_up 11 thumb_down 0 flag 0
Recursion :
During recursion, there may exist a case where same sub-problems are solved multiple times.
Consider the example of calculating nth fibonacci number.
fibo(n) = fibo(n-1) + fibo(n-2)
ffibo(n-1) = fibo(n-2) + fibo(n-3)
fibo(n-2) = fibo(n-3) + ffibo(n-4)
.................................
................................
................................
fibo(2) = fibo(1) + fibo(0)
In the first three steps, it can be clearly seen that fibo(n-3) is calculated twice. If one goes deeper into recursion, he/she may find repeating the same sub-problems again and again.
Dynamic programming is a technique where you store the result of previous calculation to avoid calculating the same once again. DP is basically a memorization technique which uses a table to store the results of sub-problem so that if same sub-problem is encountered again in future, it could directly return the result instead of re-calculating it.
Follow the below link for more details:
Dynamic Programming | Set 1 (Overlapping Subproblems Property) - GeeksforGeeks
thumb_up 0 thumb_down 0 flag 0
A semaphore has two parts : a counter, and a list of tasks waiting to access a particular resource.
A semaphore performs two operations : wait (P) [this is like acquiring a lock], and release (V) [ similar to releasing a lock] - these are the only two operations that one can perform on a semaphore.
In a binary semaphore, the counter logically goes between 0 and 1. You can think of it as being similar to a lock with two values : open/closed. A counting semaphore has multiple values for count.
Binary semaphore cannot handle Bounded wait as its just a variable that hold binary value.Counting semaphore It can handle bounded wait as it has converted a variable into an structure with a Queue.
Strcuture implementationBinary semaphore: int s; andCounting Semaphore: Struct S { int s; Queue q; }
Using the counting semaphore now process once gained the CS(Critical Section) now has to wait for the other to get the CS, so not a single process starve. Each process get a chance for CS.
thumb_up 4 thumb_down 1 flag 0

thumb_up 1 thumb_down 2 flag 0

thumb_up 3 thumb_down 3 flag 0
Mozilla Firefox :
Mozilla Firefox is a open source web browser developed by Mozilla Foundation. It was first launched in September 23, 2002. It is a freeware browser. It supports many media codes including WebM, Ogg Theora Vorbis, Ogg Opus, WAVE PCM, AAC and MP3. Its auto updates are available. Google is its default search engine.
Chrome :
Google Chrome is a web browser developed by Google Inc. It was first launched on September 2, 2008. It supports many media codes including Vorbis, WebM,Theora, MP3 and H.264. Its auto updates are available. Google is its default search engine.
Key Differences
- Mozilla Firefox is completely open source browser while Google Chrome is not completely open source web browser.
- Firefox was first launched on September 23, 2002 while Chrome was first launched on September 2, 2008.
- Flash Player for Chrome is built-in Plugin while in Firefox plugin is available but not built in.
- Firefox has MPL license while Chrome is free under Google terms of services.
- Software related to Firefox is "Firefox OS" while that to Chrome is "Chrome OS".
- Firefox is written in C/C++, CSS, XUL. XBL and JavaScript while Chrome is written in C++ and Python.
- In Firefox PDF viewer is supported without plugin but in Chrome PDF viewer is supported with built-in plugin which can be disabled.
- Firefox has given its 27th latest stable release while Chrome has given its 30th latest stable release.
thumb_up 0 thumb_down 0 flag 0
C :
C is an old system programming language developed by Dennis Ritchie in 1969. C has been accepted as an easy, flexible and powerful language used for programming of many applications, either it is for engineering programs or business programs. It was the upgraded version of B language of that time. UNIX operating system was the first operating system written in C and latest operating system like Windows and Linux, are also written in C language. Many computer architectures and operating systems are using this language. The advantages of C language are that it is a most reliable, portable, flexible, efficient, effective and interactive programming language. It is widely used in developing database systems, word processors, spreadsheets and operating system developments. At present 19% of the programs are developed in C programming language.
C# :
C# or See-Sharp is another programming language developed by Microsoft to compete with Sun's Java programming language. It is used in .NET platforms to improve and develop the web applications. C# is a simple, latest and object oriented programming language, which can be easily incorporated to Common Language Infrastructure (CLI). At that time there are four versions of C# and in future more three version will be issued by Microsoft. Latest version being used is C# 5.0. It is most suitable in writing host and embedded systems applications. The advantage of using C# language is that it provides massive library of .NET Framework, garbage collection, autoboxing, supports for threads, etc. It is little advanced and updated than C and C++. Its garbage collector features allows the users to automatically manages the unreachable objects. At present 5% of the programs are developed in C# programming language.
Key Differences
- C programming language is more suitable for system programming apps, hardware apps, embedded device and chip designing. While C# is suitable for apps development and web apps development.
- Both C and C# deals in four basic data type like int, float, double and char. C# has one addition data type feature Booleans, which is used to shows the output of logical operations.
- Total 32 keywords are used in C programming language while in C# total 87 keywords are used.
- C# has more integral type as compare to C. There is only one type of integral in C, which are two in C#, char type and whole number which can be signed or unsigned.
- C is a structure oriented programming language while C# is an object oriented language.
- Top down approach program structure is followed by C while bottom up approach program structure is adopted by C#.
thumb_up 0 thumb_down 0 flag 0
The Task Manager is a useful tool for monitoring system activity, terminating misbehaving processes, and performing some high-level performance analysis. It runs at a higher priority than normal applications, and it has sufficient privilege to view and control the system's running processes. There are a couple of ways to invoke the task manager: either right-click the task bar and choose "Start Task Manager" from the Context menu, or pressCtrl+Shift+Esc. Either way, Windows displays the Task Manager.

Figure 1. The Applications tab of the Windows Task Manager.
Notice that there are six tabs:
Applications, Processes, Services, Performance, Networking, and Users. The tab that initially gets the focus is the tab that had the focus the last time the Task Manager was used.
1. Applications
TheApplicationstab in Task Manager shows a list of programs currently running. A set of rules determines whether a process appears on this tab or not. Most applications that have a taskbar entry will appear on this tab, but this is not always the case.
Right-clicking any of the applications in the list allows (among other things) switching to that application, ending the application, and showing the process on theProcesses tab that is associated with the application.
Choosing toEnd Task from theApplications tab causes a request to be sent to the application for it to terminate. This is different from what happens whenEnd Process is chosen from theProcesses tab.
2. Processes
TheProcessestab shows a list of all running processes on the system. This list includes Windows Services and processes from other accounts. Prior to Windows XP, process names longer than 15 characters in length are truncated. Beginning with Windows XP, theDelete key can also be used to terminate processes on the Processes tab.
Right-clicking a process in the list allows changing the priority the process has, setting processor affinity (setting which CPU(s) the process can execute on), and allows the process to be ended. Choosing toEnd Process causes Windows to immediately kill the process. Choosing to "End Process Tree" causes Windows to immediately kill the process, as well as all processes directly or indirectly started by that process. Unlike choosingEnd Task from theApplications tab, when choosing toEnd Process the program is not given warning nor a chance to clean up before ending. However, when a process that is running under a security context different from the one of the process which issued the call to TerminateProcess, the use of the KILL command line utility is required.
By default the processes tab shows the user account the process is running under, the amount of CPU, and the amount of memory the process is currently consuming. There are many more columns that can be shown by choosingSelect columns... from theView menu.
3. Services
The Services tab displays information about the Windows services installed on your system. By right-clicking on a service, you can start a stopped service, stop a running service, or immediately go to the process using a service. By clicking theServices button you can bring up the Services application, where you have full control over your services.
4. Performance
Theperformancetab shows overall statistics about the system's performance, most notably the overall amount of CPU usage and how much memory is being used. A chart of recent usage for both of these values is shown. Details about specific areas of memory are also shown.
There is an option to break the CPU usage graph into two sections: kernel mode time and user mode time. Many device drivers, and core parts of the operating system run in kernel mode, whereas user applications run in user mode. This option can be turned on by choosingShow kernel times from theView menu. When this option is turned on the CPU usage graph will show a green and a red area. The red area is the amount of time spent in kernel mode, and the green area shows the amount of time spent in user mode.
5. Networking
TheNetworkingtab, introduced in Windows XP, shows statistics relating to each of the network adapters present in the computer. By default the adapter name, percentage of network utilization, link speed and state of the network adapter are shown, along with a chart of recent activity. More options can be shown by choosingSelect columns... from theView menu.
6. Users
TheUserstab, also introduced in Windows XP, shows all users that currently have a session on the computer. On server computers, there may be several users connected to the computer using Terminal Services. As of Windows XP, there may also be multiple users logged onto the computer at one time using the Fast User Switching feature. Users can be disconnected or logged off from this tab.
thumb_up 3 thumb_down 0 flag 0
Linux Operating System:
It is an operating system assembled under the model of open source software development and mostly used for server purpose. It supports a dozen of programming languages like C,C++,JAVA,PHP and many more.
Advantages:
- Low cost: You need not spend much money to obtain license as its softwares come from GNU General Public License. You can also download high quality software whenever you want, free of cost and you need not worry that your program may stop due to trail version. You can also install it in many computers without paying.
- Performance:Linux provides high performance on workstations and on networks. It also helps in making old computers sufficient and usable again and also can handle many users at a time.
- Stability: You don't have to reboot periodically to maintain performance. It can handle large number of users and does not hang up or slow down due to memory issues. Continuous up time upto a year or so is common.
- Flexibility: It is used for high performance applications, desktop applications and embedded applications. You can save disk space by installing components required for a particular use. You can restrict specific computers instead of all computers.
- Security: The security aspect of the linux is very strong as it is very secure and it is less prominent to viruses, even if there is an attack there would be immediate step taken by the developers all over the world to resolve it.
- Choice:Choice is one of the greatest advantage of Linux. It gives the power to control every aspect of the operating system. Main features that you have control is look and feel of desktop by Windows Manager and kernel.
Disadvantages:
- Understanding: To become familiar with Linux you need to have a lot of patience and desire to read and explore about it.
- Software: Linux has a limited selection of available softwares.
- Ease: Even though Linux has improved a lot in ease of use but windows is much easier.
- Hardware: Linux doesnot support many hardware devices.
Windows Operating System:
It is family of operating system from Microsoft. If programming languages such as Visual Basic.net, ASP.net, Visual C#, Visual C++ are used then it is better to opt windows hosting.
Advantages:
- Ease: Microsoft Windows has made much advancement and changes which made it easy to use the operating system. Even though it is not the easiest, it is easier than linux.
- Software: Since there are more number of Microsoft users there are more software programs, games and utilities for windows. All most all games are compatible to windows, some CPU intensive and graphic intensive games are also supported.
- Hardware: All hardware manufacturers will support Microsoft windows. Due to large number of Microsoft users and broader driver, all the hardware devices are supported.
- Front Page Extension: When using a popular web design program having windows hosting makes it lot more easier. You don't have to worry if it supported or not.
- Development:If you plan to develop windows based applications then windows platform is most suggested as linux does not support windows applications.
Disadvantage:
- Price: Microsoftwindows is costly compared to Linux as each license costs between $50.00-$100.00.
- Security: When compared to linux it is much more prone to viruses and other attacks.
- Reliability: It needs to be rebooted periodically else there is a possibility of hang up of the system.
- Software Cost:Even though the windows have softwares,games for free most of the programs will cost more than $200.
Key Differences
- Linux is available for lot of devices including varieties of computers and big range of mobile phones, tablet PC and mainframes. Windows is available for less devices than Linux. It is mostly available for desktop PC, laptops and some Windows mobile phones.
- Basic version of Linux is available free of cost while you have to pay for updated and latest version. Windows version price starts from $50 to $450. In short, paid packages of Windows are more expensive than Linux.
- Linux is an open source software and Windows is a closed source software.
- Because Linux is an open source software so whenever a users faces a threat or problem he report the same on community discussion form and developers starts to finding the solution. While Windows OS takes 2 to 3 month for correction of reported threat and error and after that releases new patches and updates.
- Red Hat, Android and Debian are examples of Linux OS. Windows XP, Vista, 7, 8 and 8.1 are examples of Windows OS.
- If you are a game lover than most of the games are supportable by Windows. While games compatible range in Linux is very low and less features are available for games.
- Torvalds is the developer of Linux and Microsoft is developing the Windows.
- Most of the drivers manufactures are providing lot of compatible graphics drivers for Windows, which are less available for Linux.
- Linux OS is most secure than Windows OS. Until now, 150 viruses have been reported to Linux, which are very less than 70,000 viruses reported to Windows.
thumb_up 3 thumb_down 1 flag 2
Yes, it is possible.
import javax.swing.Timer; import java.awt.event.*; import java.util.concurrent.ArrayBlockingQueue; class Fac { public static int fac(final int _n) { final ArrayBlockingQueue<Integer> queue = new ArrayBlockingQueue<Integer>(1); final Timer timer = new Timer(0, null); timer.addActionListener(new ActionListener() { int result = 1; int n = _n; public void actionPerformed(ActionEvent e) { result *= n; n--; if(n == 0) { try { queue.put(result); } catch(Exception ex) { } timer.stop(); } } }); timer.start(); int result = 0; try { result = queue.take(); } catch(Exception ex) { } return result; } public static void main(String[] args) { System.out.println(fac(5)); } } Or,
Use Stirling approximation for Gamma function http://en.wikipedia.org/wiki/Stirling%27s_approximation

But it will be not precise.
thumb_up 2 thumb_down 0 flag 0
Call by value
In call by value mechanism, the called function creates a new set of variables in stack and copies the values of the arguments into them.
void swap(int x, int y) { int z; z = x; x = y; y = z; printf("Swapped values are a = %d and b = %d", x, y); } int main (int argc, char *argv[]) { int a = 7, b = 4; printf("Original values are a = %d and b = %d", a, b); swap(a, b); printf("The values after swap are a = %d and b = %d", a, b); } Output :
Original Values are a = 7 and b = 4 Swapped values are a = 4 and b = 7 The values after swap are a = 7 and b = 4 This happens because when function swap() is invoked, the values of a and b gets copied onto x and y. The function actually swaps x and y while the values of the original variables a and b remain intact.
Call by value flow diagram
Here is the flow diagram describing disassembly steps, call stack and argument variables. Calling swap (a, b) can be split into some assembly steps like-
- push value of b
- push value of a
- save return address
- call function

Here one point to note is x and y are in stack. Value of a and b will be copied to x and y. Inside swap() value of x and y will be interchanged but it will not affect a and b in the main(). Please note a and b are located at the context of main() whereas x and y located at the context of swap(). When swap() function returns, this context of x and y will be lost and it will again come back to the context of a and b.
Call by reference
In call by reference mechanism, instead of passing values to the function being called, references/pointers to the original variables are passed.
void swap(int *x, int *y) { int z; z = *x; *x = *y; *y = z; printf("Swapped values are a = %d and b = %d", *x, *y); } int main (int argc, char *argv[]) { int a = 7, b = 4; printf("Original values are a = %d and b = %d", a, b); swap(&a, &b); printf("The values after swap are a = %d and b = %d", a, b); } Output :
Original Values are a = 7 and b = 4 Swapped values are a = 4 and b = 7 The values after swap are a = 4 and b = 7 This happens because when function swap() is invoked, it creates a reference for the first incoming integer a in x and the second incoming integer b in y. Hence the values of the original variables are swapped.
Call by reference flow diagram
Here is the flow diagram describing disassembly steps, call stack and argument variables. Calling swap (&a, &b) can be split into some assembly steps like-
- push address of b
- push address of a
- save return address
- call function

Here one point to note is x and y are pointers. Address of a and b will be copied to x and y. Inside swap() values of pointers will be interchanged. Dereferencing "x" which is same as accessing "a" and the same is true for y. Dereferencing addresses at x and y is same as accessing a and b accordingly. Thus values of a and b will be interchanged after the return of swap().
thumb_up 4 thumb_down 0 flag 0
students(student_id, student_name, address)
enrollment(student_id, subject_id, mark)
subject(subject_id, subject_name, department)
Create student table
CREATE TABLE STUDENTS
(
STUDENT_ID VARCHAR2(5) PRIMARY KEY,
STUDENT_NAME VARCHAR2(15),
ADDRESS VARCHAR2(25)
);
Create enrollment table
CREATE TABLE ENROLMENT
(
STUDENT_ID VARCHAR2(5) REFERENCES STUDENTS(STUDENT_ID),
SUBJECT_ID VARCHAR2(6) REFERENCES SUBJECTS(SUBJECT_ID),
MARK NUMBER(3),
PRIMARY KEY(STUDENT_ID,SUBJECT_ID)
);
Create subject table
CREATE TABLE SUBJECTS
(
SUBJECT_ID VARCHAR2(6) PRIMARY KEY,
SUBJECT_NAME VARCHAR2(20),
DEPARTMENT VARCHAR2(20)
);
thumb_up 0 thumb_down 0 flag 0
Basically, power is supplied to the motherboard and the first instructions loaded are from the BIOS, which tests the system to make sure things are working properly, then it discovers what hardware is connected to the computer, finds a bootable device (like a hard drive) loads the first sector (boot sector) of the drive and executes it. That boot sector finds the active partition and loads the first sector of that partition, which then loads the operating system which loads drivers for all your hardware and loads a user interface for you to interact with.
For detailed reading, please refer : http://www.geeksforgeeks.org/what-happens-when-we-turn-on-computer/
thumb_up 1 thumb_down 0 flag 0
According to me, "Round Robin Scheduling".
Round robin scheduling is primarily used when time sharing and multi-user-system where the primary requirement is the good response time.
- Round-robin is effective in a general-purpose, times-sharing system or transaction-processing system.
- Fair treatment for all the processes.
- Overhead on processor is low.
- Overhead on processor is low.
- Good response time for short processes.
thumb_up 7 thumb_down 0 flag 0
Windows uses a round-robin technique with amulti-level feedback queue for priority scheduling ever since NT,
Though in Vista there were some smart heuristic improvements to ensure that some processes, such as the disk defragmenter , are at a lower priority in order to not interfere with foreground processes. To the best of my knowledge, Windows 7, 8 uses the same scheduler as Vista, though there may have been minor improvements.
Multilevel feedback queue algorithm is used on windows 10.
thumb_up 0 thumb_down 1 flag 0

thumb_up 2 thumb_down 0 flag 0
-
Stored procedure will not compile again and again where simple Query compile every time then execute.
-
Stored procedure execute server side that's why it reduces network traffic. SQL query also executes on server also but if you have big query then it will take more time comparison to Stored Procedure to traverse from client side to server.
-
As pre compile code resides in database server, stored procedure provides more security and due to complicated queries can be integrated with one form ,hence it is portable also.
-
By using SQL queries we actually exposing our database design schema(design) in the code which may be changed. so we use stored procedure which are pre-compiled execute-able object which can contain one or more SQL statements. Hence stored procedures are the replica of the complex SQL statements. A stored procedure may be written to accept inputs and return output.
thumb_up 0 thumb_down 0 flag 0
Pizza can be either a Veg pizza or Non-Veg pizza of several types (like cheese pizza, onion pizza, masala-pizza etc) and will be of 4 sizes i.e. small, medium, large, extra-large.
Cold-drink can be of several types (like Pepsi, Coke, Dew, Sprite, Fanta, Maaza, Limca, Thums-up etc.) and will be of 3 sizes small, medium, large.

You can get the source code from here : https://www.javatpoint.com/builder-design-pattern
thumb_up 2 thumb_down 0 flag 0
Concurrency means multiple tasks which start, run, and complete in overlapping time periods, in no specific order.
Parallelism is when multiple tasks OR several part of a unique task literally run at the same time, e.g. on a multi-core processor.
Remember that Concurrency and parallelism are NOT the same thing.
1. Concurrency
- Concurrency is essentially applicable when we talk about minimum two tasks or more. When an application is capable of executing two tasks virtually at same time, we call it concurrent application. Though here tasks run looks like simultaneously, but essentially they MAY not.
- They take advantage ofCPU time-slicing feature of operating system where each task run part of its task and then go to waiting state. When first task is in waiting state, CPU is assigned to second task to complete it's part of task.
Operating system based on priority of tasks, thus, assigns CPU and other computing resources e.g. memory; turn by turn to all tasks and give them chance to complete. To end user, it seems that all tasks are running in parallel. This is called concurrency.

2. Parallelism
- Parallelism does not require two tasks to exist. It literally physically run parts of tasks OR multiple tasks, at the same time using multi-core infrastructure of CPU, by assigning one core to each task or sub-task.
Parallelism requires hardware with multiple processing units, essentially. In single core CPU, you may get concurrency but NOT parallelism.

Differences between concurrency vs. parallelism
- Concurrency is when two tasks can start, run, and complete in overlapping time periods. Parallelism is when tasks literally run at the same time, eg. on a multi-core processor.
- Concurrency is the composition of independently executing processes, while parallelism is the simultaneous execution of (possibly related) computations.
- Concurrency is aboutdealing with lots of things at once. Parallelism is aboutdoing lots of things at once.
- An application can be concurrent – but not parallel, which means that it processes more than one task at the same time, but no two tasks are executing at same time instant.
- An application can be parallel – but not concurrent, which means that it processes multiple sub-tasks of a task in multi-core CPU at same time.
- An application can be neither parallel – nor concurrent, which means that it processes all tasks one at a time, sequentially.
- An application can be both parallel – and concurrent, which means that it processes multiple tasks concurrently in multi-core CPU at same time .
thumb_up 0 thumb_down 0 flag 0
In Java, if you have a Runnable like this :
Runnable runnable = newRunnable(){ public void run(){ System.out.println("Run"); } } You can easily run it in a new thread :
new Thread(runnable).start(); This is very simple and clean, but what if you've several long running tasks that you want to load in parallel and then wait for the completion of all the tasks: it's a little bit harder to code. And if you want to get the return value of all the tasks it becomes really difficult to maintain good code. But as with almost any problem, Java has a solution for you, the Executors. This simple class allows you to create thread pools and thread factories.
A thread pool is represented by an instance of the class ExecutorService. With an ExecutorService, you can submit task that will be completed in the future. Here are the type of thread pools you can create with the Executors class :
- Single Thread Executor : A thread pool with only one thread. So all the submitted tasks will be executed sequentially. Method :Executors.newSingleThreadExecutor()
- Cached Thread Pool : A thread pool that creates as many threads it needs to execute the task in parrallel. The old available threads will be reused for the new tasks. If a thread is not used during 60 seconds, it will be terminated and removed from the pool. Method :Executors.newCachedThreadPool()
- Fixed Thread Pool : A thread pool with a fixed number of threads. If a thread is not available for the task, the task is put in queue waiting for an other task to ends. Method :Executors.newFixedThreadPool()
- Scheduled Thread Pool : A thread pool made to schedule future task. Method :Executors.newScheduledThreadPool()
- Single Thread Scheduled Pool : A thread pool with only one thread to schedule future task. Method :Executors.newSingleThreadScheduledExecutor()
Once you have a thread pool, you can submit task to it using the different submit methods. You can submit a Runnable or a Callable to the thread pool. The method return a Future representing the future state of the task. If you submitted a Runnable, the Future object return null once the task finished.
For example, if you have this Callable :
private final class StringTask extends Callable<String>{ publicString call(){ //Long operations return"Run"; } } If you want to execute that task 10 times using 4 threads, you can use this code :
ExecutorService pool = Executors.newFixedThreadPool(4); for(int i =0; i <10; i++){ pool.submit(new StringTask()); } But you must shutdown the thread pool in order to terminate all the threads of the pool :
pool.shutdown();
If you don't do that, the JVM risks to not shutdown because there is still unterminated threads. You can also force the shutdown of the pool using shutdownNow. With that the currently running tasks will be interrupted and the tasks not started will not be started at all.
thumb_up 7 thumb_down 0 flag 1
Step 1: Requirements clarifications: You ALWAYS have to ask questions to find the exact scope of the problem you're solving. Design questions don't have ONE correct answer, that's why clarifying ambiguities early on becomes extremely important.
Here're some example questions for designing Twitter that should be answered before moving on to next steps:
- Will users of our service be able to post tweets and follow other people?
- Should we also design to create and display user's timeline?
- Will tweets contain photos and videos?
- Will users be able to search tweets?
- Do we need to display hot trending topics?
- Would there be any push notification for new (or important) tweets?
All such question will determine how our end design will look like.
Step 2: System interface definition: Define what APIs are expected from the system would not only establish the exact contract expected from the system but also ensure if you haven't gotten any requirement wrong. Some examples for our Twitter-like service would be:
postTweet (user_id, tweet_data, tweet_location, user_location, timestamp, …)
generateTimeline (user_id, current_time, user_location, …)
Step 3: Back-of-the-envelope estimation: It's always a good idea to estimate the scale of the system you're going to design. This'll also help later, when you'll be focusing on scaling, partitioning, load balancing and caching.
- What scale is expected from the system (e.g., number of new tweets, number of tweet views, how many timeline generations per sec., etc.)?
- How much storage would we need? We'll have different numbers if users can have photos and videos in their tweets.
Step 4: Defining data model: Defining the system data model early on, will clarify how data will flow among different components of the system and later will also guide you towards data partitioning and management. You should be able to identify various entities of the system, how they will interact with each other and different aspect of data management like storage, transportation, encryption, etc. Here're some entities for our Twitter-like service:
User : UserID, Name, Email, DoB, CreationData, LastLogin, etc.
Tweet : TweetID, Content, TweetLocation, NumberOfLikes, TimeStamp, etc.
UserFollowos : UserdID1, UserID2
FavoriteTweets : UserID, TweetID, TimeStamp
Step 5: High-level design: Draw a block diagram with 5-6 boxes representing core components of your system. You should identify enough components that're needed t to solve the actual problem from end-to-end.
For Twitter, at a high level, we would need multiple application servers to serve all the read/write requests with load balancers in front of them for traffic distributions. If we're assuming that we'll have a lot more read traffic (as compared to write), we can decide to have separate servers for handling these scenarios. On the backend, we need an efficient database that can store all the tweets and can support a huge number of reads. We would also need a distributed file storage system to store photos and videos.
Step 6: Detailed design: Dig deeper into 2-3 components; interviewers feedback should always guide you towards which parts of the system she wants you to explain further. You should be able to provide different approaches, their positives and negatives, and why would you choose one? Remember there is no single answer, only thing important is to consider tradeoffs between different options while keeping system constraints in mind.
- Since we'll be storing a huge amount of data, how should we partition our data to distribute it to multiple databases? Should we try to store all the data of a user on the same database? What issue can it cause?
- How would we handle hot users, who tweet a lot or follow a lot of people?
- How much and at which layer should we introduce cache to speed things up?
Step 7: Bottlenecks: Try to discuss as many bottlenecks as possible and different approaches to mitigate them.
- Is there any single point of failure in our system? What are we doing to mitigate it?
- Do we've enough replicas of the data, so that if we lose a few servers, we can still serve our users?
For further knowledge about system design on twitter , please read : System Design Interview Question – How to Design Twitter
thumb_up 7 thumb_down 1 flag 0

thumb_up 0 thumb_down 0 flag 0
This is java program to generate the random numbers, using the Park-Miller algorithm. Park–Miller random number generator is a variant of linear congruential generator (LCG) that operates in multiplicative group of integers modulo n. A general formula of a random number generator (RNG) of this type is, x(n+1) = g*x(n) mod n.
Here is the source code of the Java Program to Implement Park-Miller Random Number Generation Algorithm.
//This is a sample program to random numbers using Park Miller Random Numbers algorithm public class Park_Miller_Random_Numbers { static final long m = 2147483647L; static final long a = 48271L; static final long q = 44488L; static final long r = 3399L; static long r_seed = 12345678L; public static double uniform () { long hi = r_seed / q; long lo = r_seed - q * hi; long t = a * lo - r * hi; if (t > 0) r_seed = t; else r_seed = t + m; return r_seed; } public static void main (String[] argv) { double[] A = new double [10]; for (int i=0; i<5; i++) A[i] = uniform(); for (int i=0; i<5; i++) System.out.print (" " + A[i]); } } thumb_up 1 thumb_down 0 flag 0
Definitions
REST :
REST is used when you are exposing a public API over the internet to handle CRUD operations on data. REST is focused on accessing named resources through a single consistent interface.
SOAP :
SOAP brings it's own protocol and focuses on exposing pieces of application logic (not data) as services. SOAP exposes operations. SOAP is focused on accessing named operations, each implement some business logic through different interfaces.
Though SOAP is commonly referred to as "web services" this is a misnomer. SOAP has very little if anything to do with the Web. REST provides true "Web services" based on URIs and HTTP.
By way of illustration here are few calls and their appropriate home with commentary.
getUser(User); This is a rest operation as you are accessing a resource (data).
switchCategory(User, OldCategory, NewCategory) This is a SOAP operation as you are performing an operation.
Yes, either could be done in either SOAP or REST. The purpose is to illustrate the conceptual difference.
Why REST?
Here are a few reasons why REST is almost always the right answer.
1. Since REST uses standard HTTP it is much simpler in just about ever way. Creating clients, developing APIs, the documentation is much easier to understand and there aren't very many things that REST doesn't do easier/better than SOAP.
2. REST permits many different data formats where as SOAP only permits XML. While this may seem like it adds complexity to REST because you need to handle multiple formats, in my experience it has actually been quite beneficial. JSON usually is a better fit for data and parses much faster. REST allows better support for browser clients due to it's support for JSON.
3. REST has better performance and scalability. REST reads can be cached, SOAP based reads cannot be cached.
Why SOAP?
Here are a few reasons you may want to use SOAP.
1. WS-Security
While SOAP supports SSL (just like REST) it also supports WS-Security which adds some enterprise security features. Supports identity through intermediaries, not just point to point (SSL). It also provides a standard implementation of data integrity and data privacy. Calling it "Enterprise" isn't to say it's more secure, it simply supports some security tools that typical internet services have no need for, in fact they are really only needed in a few "enterprise" scenarios.
2. WS-AtomicTransaction
Need ACID Transactions over a service, you're going to need SOAP. While REST supports transactions, it isn't as comprehensive and isn't ACID compliant. Fortunately ACID transactions almost never make sense over the internet. REST is limited by HTTP itself which can't provide two-phase commit across distributed transactional resources, but SOAP can. Internet apps generally don't need this level of transactional reliability, enterprise apps sometimes do.
3. WS-ReliableMessaging
Rest doesn't have a standard messaging system and expects clients to deal with communication failures by retrying. SOAP has successful/retry logic built in and provides end-to-end reliability even through SOAP intermediaries.
Summary
In Summary, SOAP is clearly useful, and important. For instance, if I was writing an iPhone application to interface with my bank I would definitely need to use SOAP. All three features above are required for banking transactions. For example, if I was transferring money from one account to the other, I would need to be certain that it completed. Retrying it could be catastrophic if it succeed the first time, but the response failed.
thumb_up 1 thumb_down 0 flag 0
First create the following demo_file that will be used in the examples below to demonstrate grep command.
$ cat demo_file THIS LINE IS THE 1ST UPPER CASE LINE IN THIS FILE. this line is the 1st lower case line in this file. This Line Has All Its First Character Of The Word With Upper Case. Two lines above this line is empty. And this is the last line. 1. Search for the given string in a single file
The basic usage of grep command is to search for a specific string in the specified file as shown below.
Syntax: grep "literal_string" filename $ grep "this" demo_file this line is the 1st lower case line in this file. Two lines above this line is empty. And this is the last line. 2. Checking for the given string in multiple files.
Syntax: grep "string" FILE_PATTERN This is also a basic usage of grep command. For this example, let us copy the demo_file to demo_file1. The grep output will also include the file name in front of the line that matched the specific pattern as shown below. When the Linux shell sees the meta character, it does the expansion and gives all the files as input to grep.
$ cp demo_file demo_file1 $ grep "this" demo_* demo_file:this line is the 1st lower case line in this file. demo_file:Two lines above this line is empty. demo_file:And this is the last line. demo_file1:this line is the 1st lower case line in this file. demo_file1:Two lines above this line is empty. demo_file1:And this is the last line. 3. Case insensitive search using grep -i
Syntax: grep -i "string" FILE This is also a basic usage of the grep. This searches for the given string/pattern case insensitively. So it matches all the words such as "the" , "THE" and "The" case insensitively as shown below.
$ grep -i "the" demo_file THIS LINE IS THE 1ST UPPER CASE LINE IN THIS FILE. this line is the 1st lower case line in this file. This Line Has All Its First Character Of The Word With Upper Case. And this is the last line. 4. Match regular expression in files
Syntax: grep "REGEX" filename This is a very powerful feature, if you can use use regular expression effectively. In the following example, it searches for all the pattern that starts with "lines" and ends with "empty" with anything in-between. i.e To search "lines[anything in-between]empty" in the demo_file.
$ grep "lines.*empty" demo_file Two lines above this line is empty. From documentation of grep: A regular expression may be followed by one of several repetition operators:
- ? The preceding item is optional and matched at most once.
- * The preceding item will be matched zero or more times.
- + The preceding item will be matched one or more times.
- {n} The preceding item is matched exactly n times.
- {n,} The preceding item is matched n or more times.
- {,m} The preceding item is matched at most m times.
- {n,m} The preceding item is matched at least n times, but not more than m times.
5. Checking for full words, not for sub-strings using grep -w
If you want to search for a word, and to avoid it to match the substrings use -w option. Just doing out a normal search will show out all the lines.
The following example is the regular grep where it is searching for "is". When you search for "is", without any option it will show out "is", "his", "this" and everything which has the substring "is".
$ grep -i "is" demo_file THIS LINE IS THE 1ST UPPER CASE LINE IN THIS FILE. this line is the 1st lower case line in this file. This Line Has All Its First Character Of The Word With Upper Case. Two lines above this line is empty. And this is the last line.
The following example is the WORD grep where it is searching only for the word "is". Please note that this output does not contain the line "This Line Has All Its First Character Of The Word With Upper Case", even though "is" is there in the "This", as the following is looking only for the word "is" and not for "this".
$ grep -iw "is" demo_file THIS LINE IS THE 1ST UPPER CASE LINE IN THIS FILE. this line is the 1st lower case line in this file. Two lines above this line is empty. And this is the last line. For further applications , you can read the article : http://www.thegeekstuff.com/2009/03/15-practical-unix-grep-command-examples
thumb_up 2 thumb_down 0 flag 0
LFU Cache Algorithm
LFU is a cache eviction algorithm calledleast frequently used cache. In LFU we check the old page as well as the frequency of that page and if frequency of the page is lager than the old page we cant remove it and if we all old pages are having same frequency then take last i.e FIFO method for that and remove page.
Data structure
It requires three data structures.
- One is ahash table which is used to cache the key/values so that given a key we can retrieve the cache entry at O(1).
- Second one is adouble linked list for each frequencyof access. The max frequency is capped at the cache size to avoid creating more and more frequency list entries. If we have a cache of max size 4 then we will end up with 4 different frequencies. Each frequency will have a double linked list to keep track of the cache entries belonging to that particular frequency.
- The third data structure would be to somehow link these frequencies lists. It can be either anarray or another linked list so that on accessing a cache entry it can be easily promoted to the next frequency list in time O(1).
thumb_up 0 thumb_down 0 flag 0
3 ways to parse String to float in Java
There are mainly three ways to convert String to float value in Java,
- using Float.valueOf(),
- Float.parseFloat() method and
- by using constructor of Float class, which accepts a String.
All these methods throws NumberFormatException if float value is illegal or not parsable.
For example trying to convert a String "#200.2" will throw Exception in thread "main" java.lang.NumberFormatException: For input string: "#200.2". By the way it's legal to pass suffix "f" or "F" along with floating point number e.g. "200.2F" will not throw this error.
Similarly, you can also use same technique to parse any negative floating point number String to float in Java, minus sign (-) is permitted in float String. You can use code snippets given in example section to parse String to float in Java. One thing, which is worth remembering, while dealing with String and float is that, comparing them in String format and as float values may return different result.
As shown in following example
float f1 = 414.23f; float f2 = Float.valueOf("414.23f"); String s1 = "414.23f"; String s2 = String.valueOf(f1); boolean result1 = (f1 == f2); boolean result2 = s1.equals(s2); System.out.printf("Comparing floating point numbers %f and %f as float" + " returns %b %n", f1, f2, result1); System.out.printf("Comparing floating point numbers %s and %s as String" + " returns %b %n", s1, s2, result2); Output: Comparing floating point numbers 414.230011 and 414.230011 as float returns true Comparing floating point numbers 414.23f and 414.23 as String returns false
The reason, we get false is because of "f" suffix present in String, which is not very uncommon. Also, it's good idea to remove white spaces from String before converting them to float in Java.
thumb_up 3 thumb_down 0 flag 0

thumb_up 4 thumb_down 1 flag 0
Observations:
1. Sum of outcome of dices must lie between 1 and 12 (both inclusive)
2. Each of out the sum should have equal probability
Conclusions:
1. Second dice must have 0 and 6 (direct from observation #1 since first dice contains 1-6)
2. Now counting the outcomes:
1-6 will appear once when 0 face on second dice comes
7-12 will appear once when 6 face on second dice comes
Hence, if we repeat 0 on two more faces and 6 on remaining two faces so that three faces on second dice contains 0 and three other faces contains 6.
Then, counting the sum of outcome we will have
1-6 will appear 3 times (0 on second dice and corresponding outcome on other)
7-12 will also appear 3 times (6 on second dice and remaining on first dice)
Therefore answer should be:
On second dice mark 0 on three faces and 6 on remaining three faces.
1st dice: 1, 2, 3, 4, 5, 6
2nd dice: 0, 0, 0, 6, 6, 6
thumb_up 2 thumb_down 0 flag 0

thumb_up 3 thumb_down 0 flag 0
What is an immutable class and Object.
Immutable class is a class which once created, it's contents can not be changed. Immutable objects are the objects whose state can not be changed once constructed. e.g. String class
How to create an immutable class?
To create an immutable class following steps should be followed:
-
Create a final class.
-
Set the values of properties using constructor only.
-
Make the properties of the class final and private
-
Do not provide any setters for these properties.
-
If the instance fields include references to mutable objects, don't allow those objects to be changed:
-
Don't provide methods that modify the mutable objects.
-
Don't share references to the mutable objects. Never store references to external, mutable objects passed to the constructor; if necessary, create copies, and store references to the copies. Similarly, create copies of your internal mutable objects when necessary to avoid returning the originals in your methods.
-
public final class Immutable { private final String name; final private List<String> phenenos; public Immutable(String name, List<String> phenenos) { this.name = name; phenos = Collections.unmodifiableList(phenenos); } public String getName() { return this.name; } public List<String> getPhenenos() { return phenenos; } // No setter; } thumb_up 0 thumb_down 0 flag 0
AJAX =AsynchronousJavaScriptAndXML. AJAX is not a programming language.
AJAX just uses a combination of:
- A browser built-in XMLHttpRequest object (to request data from a web server)
- JavaScript and HTML DOM (to display or use the data)
AJAX allows web pages to be updated asynchronously by exchanging data with a web server behind the scenes. This means that it is possible to update parts of a web page, without reloading the whole page.
How AJAX Works
1. An event occurs in a web page (the page is loaded, a button is clicked)
2. An XMLHttpRequest object is created by JavaScript
3. The XMLHttpRequest object sends a request to a web server
4. The server processes the request
5. The server sends a response back to the web page
6. The response is read by JavaScript
7. Proper action (like page update) is performed by JavaScript
thumb_up 0 thumb_down 0 flag 0
It depends on what operations on the data structure you are interested in.
Two alternatives:
- hashmap
- trie
If you just want the count then a hash map with value = count , time: amortized O(1) , space: depends on the hash function, best case: O(unique_words).
Note : amortized O(1) means average running time per operation over a worst-case sequence of operations is constant.
#include <iostream> #include <vector> #include <unordered_map> typedef std::unordered_map<std::string, int> MyHashMap; void printMyHashMap(MyHashMap::const_iterator itr,MyHashMap::const_iterator enditr){ while(itr!=enditr){ std::cout<<(*itr).first<<" : "<<(*itr).second<<std::endl; ++itr; } } int main(){ MyHashMap wordsMap; //declare unordered map //vector of strings std::vector<std::string> strings {"count","words","in","a","file", "and","print","words","with","their","count", ".","more","words","file"}; int len = strings.size(); std::vector<std::string>::const_iterator wordsItr; wordsItr = strings.begin(); MyHashMap::iterator mapItr = wordsMap.begin(); for ( wordsItr=strings.begin(); wordsItr!=strings.end(); wordsItr++ ){ mapItr = wordsMap.find(*wordsItr); if(mapItr==wordsMap.end()){ //if word not found then wordsMap.insert(MyHashMap::value_type(*wordsItr, 1)); }else{ (*mapItr).second = ++(*mapItr).second; } } std::cout<<"words and their count :"<<std::endl; printMyHashMap(wordsMap.begin(),wordsMap.end()); return (0); } thumb_up 1 thumb_down 0 flag 0
The extra size is due to the vtable/vtable pointer that is "invisibly" added to your class in order to hold the member function pointer for a specific object of this class or it's descendant/ancestor.
There are two separate things here that cause extra overhead :
Firstly, having virtual functions in the base class increases its size by a pointer size (4 bytes in this case), because it needs to store the pointer to the virtual method table:
normal inheritance with virtual functions: 0 4 8 12 | base | | vfptr | i | j | Secondly, in virtual inheritance extra information is needed inderived to be able to locatebase. In normal inheritance the offset betweenderived andbase is a compile time constant (0 for single inheritance). In virtual inheritance the offset can depend on the runtime type and actual type hierarchy of the object. Implementations may vary, but for example Visual C++ does it something like this:
virtual inheritance with virtual functions: 0 4 8 12 16 | base | | xxx | j | vfptr | i | Wherexxx is a pointer to some type information record, that allows to determine the offset tobase.
And of course it's possible to have virtual inheritance without virtual functions:
virtual inheritance without virtual functions: 0 4 8 12 | base | | xxx | j | i | thumb_up 5 thumb_down 0 flag 0
Basic Object
- Vehicle
- size of vehicle (small, medium, large)
- status of vehicle (run or parked)
-
Sedan, SUV, Bus, Truck... extends Vehicle
-
Slot
- size of slot
- status (available or not)
-
Lot
- hold slots in lot
Diagram :

- Vehicle
public class Vehicle { private final int size; private final int lisense; private boolean status; private Lot lot; public Vehicle(int size) { this.size = size; lisense = this.hashCode(); lot = Lot.getInstance(); } public void setStatus(boolean status) { this.status = status; } private Slot findSlot() { Slot slot; switch (this.size) { case 1: slot = lot.getSmallSlots().remove(0); case 2: slot = lot.getCompactSlots().remove(0); case 3: slot = lot.getLargeSlots().remove(0); default: slot = null; } return slot; } public void park() { Slot slot = findSlot(); if (slot != null) { lot.occupiedSlots.put(this.lisense, slot); slot.occupy(this); } } public void leave() { Slot slot = lot.occupiedSlots.remove(this.lisense); slot.release(); switch (this.size) { case 1: lot.getSmallSlots().add(slot); case 2: lot.getCompactSlots().add(slot); case 3: lot.getLargeSlots().add(slot); } } } public class Car extends Vehicle{ public Car(){ super(1); } } public class Truck extends Vehicle{ public Truck(){ super(2); } } // ... other type of vehicle - Lot
public class Lot { private static Lot lot = null; private static final int NUMBER_OF_SMALL_SLOTS = 10; private static final int NUMBER_OF_COMPACT_SLOTS = 10; private static final int NUMBER_OF_LARGE_SLOTS = 10; public Map<Integer, Slot> occupiedSlots; private List<Slot> smallSlots; private List<Slot> compactSlots; private List<Slot> largeSlots; private Lot() { smallSlots = new LinkedList<>(); compactSlots = new LinkedList<>(); largeSlots = new LinkedList<>(); occupiedSlots = new HashMap<>(); for (int i = 1; i <= NUMBER_OF_SMALL_SLOTS; i++) smallSlots.add(new Slot(i, 1)); for (int i = 1; i <= NUMBER_OF_COMPACT_SLOTS; i++) compactSlots.add(new Slot(i, 2)); for (int i = 1; i <= NUMBER_OF_LARGE_SLOTS; i++) largeSlots.add(new Slot(i, 3)); } public List<Slot> getSmallSlots() { return smallSlots; } public List<Slot> getCompactSlots() { return compactSlots; } public List<Slot> getLargeSlots() { return largeSlots; } public static Lot getInstance() { if (lot == null) lot = new Lot(); return lot; } } - Slot
public class Slot { private final int id; private final int size; private boolean available; private Vehicle vehicle; public Slot(int id, int size) { this.id = id; this.size = size; this.available = true; } public void occupy(Vehicle v) { this.vehicle = v; this.available = false; } public void release() { this.vehicle = null; this.available = true; } } thumb_up 2 thumb_down 0 flag 0
Early Binding
Compiler knows at compile time which function to invoke.
Most of the function calls the compiler encounters will be direct function calls. e.g.,
int sum(int a, int b) { return a + b; } int main() { std::cout << sum(2, 3); // This is a direct function call return 0; }
Direct function calls can be resolved using a process known as early binding.Early binding (also calledstatic binding) means the compiler is able to directly associate the identifier name (such as a function or variable name) with a machine address. Remember that all functions have a unique machine address. So when the compiler encounters a function call, it replaces the function call with a machine language instruction that tells the CPU to jump to the address of the function.
Late Binding
Compiler doesn't know until runtime which function to invoke.
In some programs, it's not possible to know which function will be called until runtime. This is known aslate binding(ordynamic binding). In C++, one way to get late binding is to use function pointers or the other way is the use of virtual functions in inheritance. e.g.,
int add(int x, int y) { return x + y; } int subtract(int x, int y) { return x - y; } int main() { int x, y; std::cin >> x >> y; int operation; std::cout << "choose 0 for add & 1 for subtract\n"; std::cin >> operation; int (*p)(int, int); // Function Pointer ,Set p to point to the function the user choice switch (operation) { case 0 : p = add; break; case 1 : p = subtract; break; } // Call the function that p is pointing to std::cout << "The answer is: " << p(x, y) << std::endl; return 0; } thumb_up 3 thumb_down 3 flag 0
voidis a special data-type, because it literally means NO data type. However, void type pointers are much special - they are something calledgeneric pointers.
Imagine a scenario where there are different variables, and you need to access them, via pointers.
int i=1; float f=12.34; char *str = "an example"; you can do that in 2 ways.
1. The obvious way: declare individual pointer for each type, resulting in a longer and redundant code.
int *ptr_i = &i; float *ptr_f = &f; char *ptr_str = str; //because C strings are character pointers
2. Second way is to write generic code. Have a look below first.
void *ptr; ptr=&i; //works ptr=&f; //works ptr=str; // also works int *p --- meansp is a pointer used to holdmemory location of aninteger type of variable.
void *p --- means p is ageneric pointer used to holdmemory location ofany type of variable.
thumb_up 0 thumb_down 1 flag 0
Instead of putting your data inside the DB, you can keep them as a set of documents (text files) separately and keep the link (path/url etc.) in the DB.
This is essential because, SQL query by design will be very slow both in sub-string search as well as retrieval.
Now, your problem is formulated as, having to search the text files which contains the set of strings. There are two possibilities here.
-
Sub-string match If your text blobs is a single sting or word (without any white space) and you need to search arbitrary sub-string within it. In such cases you need to parse every file to find best possible files that matches. One uses algorithms like Boyer Moor algorithm. This is also equivalent to "grep" - because "grep" uses similar stuff inside. But you may still make at least 100+ "grep" (worst case 2 million) before returning.
-
Indexed search. Here you are assuming that text contains set of words and search is limited to fixed word lengths. In this case, document is indexed over all the possible occurrences of words. This is often called "Full Text search". There are number of algorithms to do this and number of open source projects that can be used directly. Many of them, also support wild card search, approximate search etc. as below :
a. Apache Lucene :http://lucene.apache.org/java/docs/index.html
b. OpenFTS : http://openfts.sourceforge.net/
c. Sphinx : http://sphinxsearch.com/
Most likely if you need "fixed words" as queries, the approach two will be very fast and effective.
thumb_up 1 thumb_down 0 flag 0
You can take help ofjson_encode() andjson_decode() functions of PHP solve these things.
To store and array intomysql, you should usejson_encode($yourArray); and you should store the returned string intomysql.
Similarly for retrieving, you should usejson_decode($yourMySqlStoredString) and this will return the array back to you, which you can use for your further manupulations!
Original array:
Array( [prvni] => Array ( [druhy] => Array ( [0] => a [1] => b [2] => c [3] => d [4] => e [5] => f ) ) [prvnidruhy] => Array ( [0] => 1 [1] => 2 [2] => 3 [3] => 4 [4] => 5 ) ) json_encode:
{"prvni":{"druhy":["a","b","c","d","e","f"]},"prvnidruhy":[1,2,3,4,5]} json_decode:
object(stdClass)[1] public 'prvni' => object(stdClass)[2] public 'druhy' => array (size=6) 0 => string 'a' (length=1) 1 => string 'b' (length=1) 2 => string 'c' (length=1) 3 => string 'd' (length=1) 4 => string 'e' (length=1) 5 => string 'f' (length=1) public 'prvnidruhy' => array (size=5) 0 => int 1 1 => int 2 2 => int 3 3 => int 4 4 => int 5 thumb_up 1 thumb_down 0 flag 0
If getting "no of student" and "no of subject" is the goal, we can use two maps, one with <stduent id, no_of_subject> pair as an element and the other one with <subject id, no_of_students> pair as an element.
However, if the goal is to retrieve students taking a specific subject or retrieve subjects that a specific student is taking, I would use two maps (or hashtable):
- stduent hash map: key => stduent id , value => list of subject ids(either linked list or std::vector)
- subject hash map: key=> subject id, value=> list of student ids(either linked list or std::vector)
A combination of this should work:
- HashMap of student to list of subjects
- HashMap of subject to list of students
This allows for expectedO(1) retrieval of either the list of subjects a student is taking, or the list of students that's taking a subject (presumably the list structure will store a count to allowO(1) retrieval of the number of elements).
The space complexity isO(n).
If you only want the counts, you could consider replacing the "list of students" (and perhaps even "list of subjects") with simply a count.
If you want to support removal or existence checks, "list of subjects" or "list of students" is not going to be particularly efficient. To do so efficiently, you could replace those lists with HashSets.
thumb_up 3 thumb_down 0 flag 0
This question can be seen as 0/1 Knapsack problem with
knapsack of capacity W = 10
int val[] = {4, 3, 2, 10, 5};
int wt[] = {1, 2, 3, 4, 5};
Now apply the Knapsack algorithm
int max(int a, int b) { return (a > b)? a : b; } // Returns the maximum value that can be put in a knapsack of capacity W int knapSack(int W, int wt[], int val[], int n) { int i, w; int K[n+1][W+1]; // Build table K[][] in bottom up manner for (i = 0; i <= n; i++) { for (w = 0; w <= W; w++) { if (i==0 || w==0) K[i][w] = 0; else if (wt[i-1] <= w) K[i][w] = max(val[i-1] + K[i-1][w-wt[i-1]], K[i-1][w]); else K[i][w] = K[i-1][w]; } } return K[n][W]; } thumb_up 5 thumb_down 1 flag 0
SELECT Student.sid FROM Student S INNER JOIN Class C ON S.sid = C.cid GROUP BY S.sid, HAVING COUNT(*) > 1 thumb_up 0 thumb_down 0 flag 0
This database design is relatively straightforward. Because its purpose is to record reservations, the Reservations table is right in the center.

thumb_up 0 thumb_down 0 flag 0
C++98/03
If they are needed,
- the compiler will generate adefault constructor for you unless you declare any constructor of your own.
- the compiler will generate a copy constructor for you unless you declare your own.
- the compiler will generate a copy assignment operator for you unless you declare your own.
- the compiler will generate adestructor for you unless you declare your own.
C++11
C++11 adds the following rules, which are also true for C++14 :
- The compiler generates the move constructor if
- there is no user-declared copy constructor, and
- there is no user-declared copy assignment operator, and
- there is no user-declared move assignment operator and
- there is no user-declareddestructor,
- it is not marked asdeleted,
- and all members and bases aremoveable.
- Similar for the move assignment operator: It is generated if there is no user defined
- there is no user-declared copy constructor, and
- there is no user-declared copy assignment operator, and
- there is no user-declared move constructor and
- there is no user-declareddestructor,
- it is not marked asdeleted,
- and all members and bases aremoveable.
Note that these rules are a bit more elaborated than the C++03 rules and make more sense in practice.
For an easier understanding of what is what of the above here the items forThing:
class Thing { public: Thing(); // default constructor Thing(const Thing&); // copy c'tor Thing& operator=(const Thing&); // copy-assign ~Thing(); // d'tor // C++11: Thing(Thing&&); // move c'tor Thing& operator=(Thing&&); // move-assign }; thumb_up 5 thumb_down 0 flag 0
Virtual memory (transferring from physical RAM to the hard disk) theoretically allows processes to take as much memory as they want (within the limit of the hard disk obviously).
However, since disk access is many orders of magnitude slower than RAM access, the more of the process can live in RAM the better.
Also, virtual memory only really works well as long as there is a pattern to data access. If things keep having to get written out to disk after every access (because they are not in RAM) then performance is catastrophic.
thumb_up 1 thumb_down 0 flag 0
It should run indefinitely. On most platforms, when there's no more memory available,malloc() will return 0, so the loop will keep on running without changing the amount of memory allocated.
Linux allows memory over-commitment so thatmalloc() calls continue to add to virtual memory. The process might eventually get killed by the OOM Killer when the data thatmalloc() uses to administer the memory starts to cause problems (it won't be because you try using the allocated memory itself because the code doesn't use it).
thumb_up 0 thumb_down 0 flag 0
Given that little piece of background information, here's how we can sort theps command output by memory usage:
ps aux --sort -rss
That ps command gives me this output:
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND mysql 2897 0.0 1.7 136700 17952 ? Sl Oct21 0:00 /usr/libexec/mysqld --basedir=/usr --datadir=/var/lib/mysq root 2483 0.0 1.0 43540 11368 ? Ssl Oct21 0:00 /usr/bin/python -E /usr/sbin/setroubleshootd root 3124 0.0 0.9 25816 10332 ? SN Oct21 0:00 /usr/bin/python -tt /usr/sbin/yum-updatesd root 2406 0.0 0.9 11572 10004 ? Ss Oct21 0:00 /usr/sbin/restorecond root 2928 0.0 0.6 17648 7120 ? Ss Oct21 0:00 /usr/local/apache2/bin/httpd -k start nobody 2949 0.0 0.6 17648 6492 ? S Oct21 0:00 /usr/local/apache2/bin/httpd -k start nobody 2950 0.0 0.6 17648 6492 ? S Oct21 0:00 /usr/local/apache2/bin/httpd -k start nobody 2951 0.0 0.6 17648 6492 ? S Oct21 0:00 /usr/local/apache2/bin/httpd -k start nobody 2952 0.0 0.6 17648 6492 ? S Oct21 0:00 /usr/local/apache2/bin/httpd -k start nobody 2953 0.0 0.6 17648 6492 ? S Oct21 0:00 /usr/local/apache2/bin/httpd -k start 68 3115 0.0 0.3 5920 3912 ? Ss Oct21 0:01 hald root 18453 0.0 0.2 10140 2884 ? Ss 11:09 0:00 sshd: root@pts/0 root 2801 0.0 0.2 10020 2328 ? Ss Oct21 0:00 cupsd root 2959 0.0 0.1 9072 1876 ? Ss Oct21 0:00 sendmail: accepting connections root 475 0.0 0.1 3004 1600 ? S<s Oct21 0:00 /sbin/udevd -d
As you can see, this prints the ps output with the largest RSS size at the top of the output. (There are also many more lines than this, I just trimmed the output.)
To reverse this output and show the largest RSS value at the bottom of the ps command output, just take the "-" sign off therss sort argument, like this:
ps aux --sort rss
To sort the output of the ps command by pid, we'd issue one of the following two commands. First, to sort by pid, in order from highest PID to lowest, we'd use this ps command:
ps aux --sort -pid
And to sort by pid, from low to high, again we remove the "-" from our argument:
ps aux --sort pid
thumb_up 1 thumb_down 0 flag 0
To view only the processes owned by a specific user, use the following command:
top -U [username] Replace the [username] with the required username
If you want to use ps then
ps -u [username] OR
ps -ef | grep <username> OR
ps -efl | grep <username> for the extended listing
Another alternative is to use pstree which prints the process tree of the user
pstree <username or pid> thumb_up 0 thumb_down 0 flag 0
Use kill command to send a signal to a process. For example, if you want to send USR1 signal to the process "a.out", do the following.
$ ps -C a.out PID TTY TIME CMD 3699 pts/1 00:00:00 a.out $ kill -s USR1 3699
thumb_up 8 thumb_down 1 flag 0
Start with 1 ball, one of the two identical ones. It can be distributed into 3 distinct boxes in 3 ways, obviously.
Now take the other identical ball. You can also distribute this one into the 3 distinct boxes in 3 ways. Because the two balls areidentical, we note that there are onlysix possible arrangements. If they weren't identical, there would be nine, by the multiplication rule. But they're identical, so the possible box arrangements are: {[2,0,0],[0,2,0],[0,0,2],[1,1,0],[0,1,1],[1,0,1]} . Okay, Now we have six ways to arrange the two balls into the boxes.
Now we take thedistinct ball. There are, again, three ways to arrange this one into the boxes. By the multiplication rule, we now have 3*6=18 ways to arrange the three balls into the boxes.
We have two distinct balls, so we repeat the last step again, for 3*18=54 total ways to arrange these four balls.
thumb_up 8 thumb_down 0 flag 0
You are better off shooting again without spinning the barrel.
Given that the gun didn't fire the first time, it was pointing to one of the four empty slots. Because your enemy spun the cylinder randomly, it would have been pointing to any of these empty slots with equal probability. Three of these slots would not fire again after an additional trigger-pull, and one of them would. Thus, by not spinning the barrel, there is a 1/4 chance that pulling the trigger again would fire the gun.
Alternatively, if you spin the barrel, it will point to each of the 6 slots with equal probability. Because 2 of these 6 slots have bullets in them, there would be a 2/6 = 1/3 chance that the gun would fire after spinning the barrel.
Thus, you are better off not spinning the barrel.
thumb_up 1 thumb_down 0 flag 0
1) CREATE TABLE DEMO_STUDENT
(SID VARCHAR(5) NOT NULL, NAME VARCHAR(50) NOT NULL, MAJOR VARCHAR(30), YEAR INTEGER, GPA DECIMAL(5,2),
CONSTRAINT STU_PK PRIMARY KEY (SID));
2) CREATE TABLE DEMO_INSTRUCTOR
(IID VARCHAR(5) NOT NULL, NAME VARCHAR(50) NOT NULL, DEPT VARCHAR(30),
CONSTRAINT INST_PK PRIMARY KEY (IID));
3) CREATE TABLE DEMO_CLASSROOM
(CRID VARCHAR(5) NOT NULL, DESCR VARCHAR(50) NOT NULL, CAP INTEGER,
CONSTRAINT CLSR_PK PRIMARY KEY (CRID));
4) CREATE TABLE DEMO_COURSE
(CID VARCHAR(5) NOT NULL, TITLE VARCHAR(50), IID VARCHAR(5) NOT NULL, HOUR INTEGER, CRID VARCHAR(30),
CONSTRAINT COURSE_PK PRIMARY KEY (CID), CONSTRAINT COUR_FKDISP1 FOREIGN KEY (IID) REFERENCES DEMO_INSTRUCTOR(IID), CONSTRAINT COUR_FK2 FOREIGN KEY (CRID) REFERENCES DEMO_CLASSROOM(CRID));
5) CREATE TABLE DEMO_REGISTRATION
(RID VARCHAR(5) NOT NULL, SID VARCHAR(5) NOT NULL, CID VARCHAR(5) NOT NULL,
CONSTRAINT REG_PK PRIMARY KEY (RID), CONSTRAINT REG_FK1 FOREIGN KEY (SID) REFERENCES DEMO_STUDENT(SID), CONSTRAINT REG_FK2 FOREIGN KEY (CID) REFERENCES DEMO_COURSE(CID));
thumb_up 9 thumb_down 0 flag 0
A better version of bubble sort, known as modified bubble sort, includes a flag that is set if an exchange is made after an entire pass over the array. If no exchange is made, then it should be clear that the array is already in order because no two elements need to be switched. In that case, the sort should end.
The new best case order for this algorithm is O(n), as if the array is already sorted, then no exchanges are made.
Modified bubble sort keeps count of the number of adjacent inversions in each pass and when there are no adjacent inversions the algorithm halts as the list will be sorted if there are no adjacent inversions.
void bubble(int a[], int n){ for(int i=0; i<n; i++){ int swaps=0; for(int j=0; j<n-i-1; j++){ if(a[j]>a[j+1]){ int t=a[j]; a[j]=a[j+1]; a[j+1]=t; swaps++; } } if(swaps==0) break; } } thumb_up 0 thumb_down 0 flag 0
When you want to control the process of reading and writing objects during the serialization and de-serialization process, have the object's class implemented thejava.io.Externalizable interface. Then you implement your own code to write object's states in thewriteExternal() method and read object's states in thereadExternal() method. These methods are defined by the Externalizable interface as follows:
- writeExternal(ObjectOutput out): The object implements this method to save its contents by calling the methods of DataOutput for its primitive values or calling the writeObject method of ObjectOutput for objects, strings, and arrays.
- readExternal(ObjectInput in): The object implements this method to restore its contents by calling the methods of DataInput for primitive types and readObject for objects, strings and arrays.
Suppose that you have a class User, then implement externalization for this class as shown in the following example:
import java.io.*; public class User implements Externalizable { // attributes // methods // externalization methods: public void writeExternal(ObjectOutput out) { // implement your own code to write objects of this class } public void readExternal(ObjectInput in) { // implement your own code to read serialized objects of this class } } An Externalization Demo Program
import java.util.*; import java.io.*; public class ExternalizationDemo { private String filePath = "C:/ABC"; public void serialize() throws IOException { User user = new User(); user.setCode(123); user.setName("Tom"); user.setBirthday(new Date()); user.setPassword("secret123"); user.setSocialSecurityNumber(1234567890); // serialize object's state FileOutputStream fos = new FileOutputStream(filePath); ObjectOutputStream outputStream = new ObjectOutputStream(fos); outputStream.writeObject(user); outputStream.close(); System.out.println("User's details before serialization:\n" + user); System.out.println("Serialization done"); } public void deserialize() throws ClassNotFoundException, IOException { FileInputStream fis = new FileInputStream(filePath); ObjectInputStream inputStream = new ObjectInputStream(fis); User user = (User) inputStream.readObject(); inputStream.close(); System.out.println("User's details afeter de-serialization:\n" + user); } public static void main(String[] args) throws ClassNotFoundException, IOException { ExternalizationDemo demo = new ExternalizationDemo(); demo.serialize(); System.out.println("\n=============\n"); demo.deserialize(); } } thumb_up 1 thumb_down 0 flag 0

onCreate():
Called when the activity is first created. This is where you should do all of your normal static set up: create views, bind data to lists, etc. This method also provides you with a Bundle containing the activity's previously frozen state, if there was one. Always followed by onStart().
onRestart():
Called after your activity has been stopped, prior to it being started again. Always followed by onStart()
onStart():
Called when the activity is becoming visible to the user. Followed by onResume() if the activity comes to the foreground, or onStop() if it becomes hidden.
onResume():
Called when the activity will start interacting with the user. At this point your activity is at the top of the activity stack, with user input going to it. Always followed by onPause().
onPause ():
Called as part of the activity lifecycle when an activity is going into the background, but has not (yet) been killed. The counterpart to onResume(). When activity B is launched in front of activity A, this callback will be invoked on A. B will not be created until A's onPause() returns, so be sure to not do anything lengthy here.
onStop():
Called when you are no longer visible to the user. You will next receive either onRestart(), onDestroy(), or nothing, depending on later user activity.
Note that this method may never be called, in low memory situations where the system does not have enough memory to keep your activity's process running after its onPause() method is called.
onDestroy():
The final call you receive before your activity is destroyed. This can happen either because the activity is finishing (someone called finish() on it, or because the system is temporarily destroying this instance of the activity to save space. You can distinguish between these two scenarios with the isFinishing() method.
When the Activityfirst time loads the events are called as below:
onCreate() onStart() onResume() When youclick on Phone button the Activity goes to the background and the below events are called:
onPause() onStop() Exit the phone dialer and the below events will be called:
onRestart() onStart() onResume() When you click theback button OR try tofinish() the activity the events are called as below:
onPause() onStop() onDestroy() For detailed reading , please follow : https://developer.android.com/reference/android/app/Activity.html#ActivityLifecycle
thumb_up 0 thumb_down 0 flag 0
You should define a constructor in your abstract class that takes a value for 'a' and call this constructor from your sub classes. This way, you would ensure that your final attribute is always initialized.
abstract class BaseClass { protected final int a; protected BaseClass(int a) { this.a = a; } } class SubClass extends BaseClass { public SubClass() { super(6); } } thumb_up 0 thumb_down 0 flag 0
Java thread pool manages the pool of worker threads, it contains a queue that keeps tasks waiting to get executed. We can useThreadPoolExecutor to create thread pool in java.
Java thread pool manages the collection of Runnable threads and worker threads execute Runnable from the queue.java.util.concurrent.Executors provide implementation ofjava.util.concurrent.Executor interface to create the thread pool in java.
First we need to have a Runnable class, named WorkerThread.java
public class WorkerThread implements Runnable { private String command; public WorkerThread(String s){ this.command=s; } @Override public void run() { System.out.println(Thread.currentThread().getName()+" Start. Command = "+command); processCommand(); System.out.println(Thread.currentThread().getName()+" End."); } private void processCommand() { try { Thread.sleep(5000); } catch (InterruptedException e) { e.printStackTrace(); } } @Override public String toString(){ return this.command; } } ExecutorService Example
import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; public class SimpleThreadPool { public static void main(String[] args) { ExecutorService executor = Executors.newFixedThreadPool(5); for (int i = 0; i < 10; i++) { Runnable worker = new WorkerThread("" + i); executor.execute(worker); } executor.shutdown(); while (!executor.isTerminated()) { } System.out.println("Finished all threads"); } } In above program, we are creating fixed size thread pool of 5 worker threads. Then we are submitting 10 jobs to this pool, since the pool size is 5, it will start working on 5 jobs and other jobs will be in wait state, as soon as one of the job is finished, another job from the wait queue will be picked up by worker thread and get's executed.
thumb_up 0 thumb_down 0 flag 0
If you try below code, you will find a scenario whereonDestroy() is indeed getting called whileonPause() andonStop() Life-cycle call backs are Skipped.
@Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); finish(); } @Override protected void onDestroy() { // TODO Auto-generated method stub super.onDestroy(); Log.e("MainActivity", "onDestroy"); } @Override protected void onPause() { // TODO Auto-generated method stub super.onPause(); Log.e("MainActivity", "onPause"); } @Override protected void onStop() { // TODO Auto-generated method stub super.onStop(); Log.e("MainActivity", "onStop"); } Hence, if you callfinish(), once Activity is created, system will invokeonDestroy() directly.
thumb_up 0 thumb_down 0 flag 0
getSupportFragmentManager().addOnBackStackChangedListener(new OnBackStackChangedListener() { public void onBackStackChanged() { // Your logic here } }); This callback will be called upon each change on the back stack - even when a fragment is added. If you want to know when a fragment was removed then add the following logic
Fragment someFragment = (Fragment)getSupportFragmentManager().findFragmentById(R.id.fragmentItem); if (someFragment == null) { // this fragment was removed from back stack } thumb_up 0 thumb_down 0 flag 0
The idea is to shuffle the elements (songs) of the array (your playlist) in place. Now this is anomalous to generating a shuffled copy of the array each time, which we don't want because it takes time. To achieve this, a simple rand() function would generate a random song. Here's how,
1. N be the total number of songs. Assign each song an id, ranging from 1 to N.
2. Our aim is to generate pseudo-random ids (a sequence of random numbers). So our parameters would be the current time and the last song id as random seed in module with N.
3. Now by|rand(time+Last_Id)|%N a pseudorandom id will be generated in the range from 1 to N and it wouldn't repeat if the space between the shuffles is less than the given time.
4. To avoid repetition between the last played songs, keep a list of M last played songs so the new pseudo-randomly selected song is not in this list. If the new song is in the list, repeat step 3.
Most media players including VLC build the shuffled list using rand() function. iTunes has an algorithm that takes into account the song genre, it's artist and BPM. Needless to say, BPM is the number of beats per minute. Lower the BPM is calmer or soothing the song. (You may check the BPM chart for various tempos)
Note: rand() is a C library function. The syntax varies for different languages, like Random() in C#.
thumb_up 0 thumb_down 0 flag 0
Thread
A thread is a concurrent unit of execution. It has its own call stack.
There are two methods to implement threads in applications.
One is providing a new class that extends Thread and overriding its run() method. The other is providing a new Thread instance with a Runnable object during its creation. A thread can be executed by calling its "start" method. You can set the "Priority" of a thread by calling its "setPriority(int)" method.
A thread can be used if you have no affect in the UI part. For example, you are calling some web service or download some data, and after download, you are displaying it to your screen. Then you need to use a Handler with a Thread and this will make your application complicated to handle all the responses from Threads.
A Handler allows you to send and process Message and Runnable objects associated with a thread's MessageQueue. Each thread has each message queue. (Like a To do List), and the thread will take each message and process it until the message queue is empty. So, when the Handler communicates, it just gives a message to the caller thread and it will wait to process.
If you use Java threads then you need to handle the following requirements in your own code:
- Synchronization with the main thread if you post back results to the user interface No default for canceling the thread No default thread pooling No default for handling configuration changes in Android
AsyncTask
AsyncTask enables proper and easy use of the UI thread. This class allows performing background operations and publishing results on the UI thread without having to manipulate threads and/or handlers. An asynchronous task is defined by a computation that runs on a background thread and whose result is published on the UI thread.
AsyncTask will go through the following 4 stages:
onPreExecute()
Invoked on the UI thread before the task is executed
doInbackground(Params..)
Invoked on the background thread immediately after onPreExecute() finishes executing.
onProgressUpdate(Progress..)
Invoked on the UI thread after a call to publishProgress(Progress...).
onPostExecute(Result)
Invoked on the UI thread after the background computation finishes.
Why should you use AsyncTask?
Easy to use for a UI Thread. (So, use it when the caller thread is a UI thread). No need to manipulate Handlers.
Service A Service is a context similar to Activity but has no GUI. A service doesn't run in a new thread!
thumb_up 7 thumb_down 2 flag 0
Let 10'splace digit is x and unit's place digit y
First milestone : 10x+y
Second milestone : 10y+x
Third milestone: 100x+y
Since the speed is uniform so
Distance covered in first Hr = Distance covered in Second Hr
(10y+x)-(10x+y) = (100x+y)-(10y+x)
After solving, we get ---->y=6x but since x and y are digits so only possible combination is x=1 and y=6,
So average speed = 45 KM/HR
thumb_up 6 thumb_down 0 flag 0
This is a classic problem that many people get wrong because they reason that half of a hen cannot lay an egg, and a hen cannot lay half an egg. However, we can get a satisfactory solution by treating this as a purely mathematical problem where the numbers represent averages.
To solve the problem, we first need to find the rate at which the hens lay eggs. The problem can be represented by the following equation, whereRATE is the number of eggs produced per hen·day:
1½ hens × 1½ days ×RATE = 1½ eggs
We convert this to fractions thus:
3/2 hens × 3/2 days ×RATE = 3/2 eggs
Multiplying both sides of the equation by 2/3, we get:
1 hen × 3/2 days ×RATE = 1 egg
Multiplying both sides of the equation again by 2/3 and solving forRATE, we get:
RATE = 2/3 eggs per hen·day
Now that we know the rate at which hens lay eggs, we can calculate how many hens (H) can produce 48 (4 dozen) eggs in six days using the following equation:
H hens × 6 days × 2/3 eggs per hen·day = 48 eggs
Solving forH, we get:
H = 48 eggs /(6 days × 2/3 eggs per hen·day) = 48/4 = 12 hens
Therefore,the farmer needs 12 hens to produce 48 eggs in 6 days.
thumb_up 10 thumb_down 1 flag 0
Steps :
- Fill the 5 liter jug from the tap.
- Empty the 5 liter jug into the 3 liter jug - leaving 2 liters in the 5 liter jug.
- Pour away the contents of the 3 liter jug.
- Fill the 3 liter jug with the 2 liters from the 5 liter jug - leaving 2 liters in the 3 liter jug.
- Fill the 5 liter jug from the tap.
- Fill the remaining 1 liter space in the 3 liter jug from the 5 liter jug.
- Leaving 4 liters in the 5 liter jug.
thumb_up 9 thumb_down 0 flag 0
In 1st bag---> Put 1 red ball
In 2nd bag---> Put the remaining 50 blue+49 red balls.
In this way
P(Red ball)= 1/2*1 + 1/2*49/99
=0.5 + 0.24747
= 0.7475
thumb_up 3 thumb_down 0 flag 0
REST stands forREpresentationalStateTransfer. REST is a web standards based architecture and uses HTTP Protocol for data communication. It revolves around resources where every component is a resource and a resource is accessed by a common interface using HTTP standard methods.
In REST architecture, a REST Server simply provides access to resources and the REST client accesses and presents the resources. Here each resource is identified by URIs/ Global IDs. REST uses various representations to represent a resource like Text, JSON and XML. JSON is now the most popular format being used in Web Services.
HTTP Methods
The following HTTP methods are most commonly used in a REST based architecture :
-
GET − Provides a read only access to a resource.
-
PUT − Used to create a new resource.
-
DELETE − Used to remove a resource.
-
POST − Used to update an existing resource or create a new resource.
-
OPTIONS − Used to get the supported operations on a resource.
Web services based on REST Architecture are known as RESTful Web Services. These web services use HTTP methods to implement the concept of REST architecture. A RESTful web service usually defines a URI (Uniform Resource Identifier), which is a service that provides resource representation such as JSON and a set of HTTP Methods.
Creating RESTFul Web Service :

thumb_up 0 thumb_down 1 flag 0
Lists, sorted trees of various types and bitmaps are the data structures traditionally used in memory management and garbage collection systems, but with most such systems, the average or amortized cost of operation is important, rather than the worst-case time .Ideally, a real-time garbage collector should be able to perform all operations in constant time, independent of the number of objects on the heap and the number of pointers in them. To achieve this, the data structures within the collector must provide operations which are are independent of these.
Linked lists and sorted trees (heaps, b-trees etc), arrays (or tables) of pointers and arrays(or tables) of counts were all considered for use in the garbage collector.Hash tables were not considered, while they can be 'tuned' if much is known beforehand about the data(or if time can be taken on-the-fly to rehash them), they do not,in general,perform in real-time.
thumb_up 0 thumb_down 0 flag 0
if you want to copy entire file as it is then
cat filename >> newfilename for three files
cat file1.txt file2.txt file3.txt >>file.txt if you want to copy line by line then
while IFS= read -r line do echo "$line" echo -e "$line\n" >>newfilename done <"filename" thumb_up 0 thumb_down 0 flag 0
As the name signifies, FTP is used for transferring files from one computer to another i.e. from a sender to receiver over Internet. It uses the TCP/IP protocols of the Internet to transfer the data safely. So it is a reliable protocol.
FTP has two versions :
-
FTP which uses the TCP protocol at transport layer.
-
TFTP which uses the UDP protocol at transport layer.
FTP has no flow control mechanism whereas TFTP has internal flow control mechanism because of which it is using UDP protocol. FTP is basically used for authorized users where users provide authentication using a login protocol, usually a username and password, whereas TFTP is used for anonymous users.
Features of FTP :
-
It is a client- server protocol which is connecting client with server directly. It is secured with SSL/TLS. It is also known as synchronous protocol because the clocks are in synchronization while downloading.
-
At the client side, the dynamic ports (> 1023 ) are used for making connections and at the server end, there are predefined or well known ports(0 to 1023) for making connections.
-
The FTP server maintains two types of connections : Data Connections which use port 20 and Control connections(Command connections) which is always in open state uses port 21 for transmission.
-
Client will always be in active open state(port which generate data) and server will always be in passive open state(state when the data is entered into the port). When connection is established, then the server will automatically create or open data connections.
thumb_up 0 thumb_down 0 flag 0
static int Sum(int value) { if (value > 0) { return value + Sum(value - 1); } else { return 0; //Change this. } } thumb_up 1 thumb_down 0 flag 0
Java Servlets are programs that run on a Web or Application server and act as a middle layer between a request coming from a Web browser or other HTTP client and databases or applications on the HTTP server.
Using Servlets, you can collect input from users through web page forms, present records from a database or another source, and create web pages dynamically.
Java Servlets often serve the same purpose as programs implemented using the Common Gateway Interface (CGI). But Servlets offer several advantages in comparison with the CGI.
-
Performance is significantly better.
-
Servlets execute within the address space of a Web server. It is not necessary to create a separate process to handle each client request.
-
Servlets are platform-independent because they are written in Java.
-
Java security manager on the server enforces a set of restrictions to protect the resources on a server machine. So servlets are trusted.
-
The full functionality of the Java class libraries is available to a servlet. It can communicate with applets, databases, or other software via the sockets and RMI mechanisms that you have seen already.
Servlets Architecture:
Following diagram shows the position of Servelts in a Web Application.
Detailed Reading of Java Servlets can be obtained from : https://www.tutorialspoint.com/servlets/index.htm
thumb_up 1 thumb_down 0 flag 0
An interface is a Java programming language construct, similar to an abstract class, that allows you to specify zero or more method signatures without providing the implementation of those methods.
There are several reasons, an application developer needs an interface, one of them is Java's feature to provide multiple inheritance at interface level. It allows you to write flexible code, which can adapt to handle future requirements. Some of the concrete reasons, why you need interface is :
1) If you only implement methods in sub classes, the callers will not be able to call them via the interface.
2) Interfaces are a way to declare a contract for implementing classes to fulfill. It's the primary tool to create abstraction and de-coupled designs between consumers and producers.
3) In short main use of interface is to facilitate polymorphism. Interface allows a class to behave like multiple types, which is not possible without multiple inheritance of class. It also ensures that you follow programming to interface than implementation pattern, which eventually adds lot of flexibility in your system.
However, an interface is different from a class in several ways, including −
-
You cannot instantiate an interface.
-
An interface does not contain any constructors.
-
All of the methods in an interface are abstract.
-
An interface cannot contain instance fields. The only fields that can appear in an interface must be declared both static and final.
-
An interface is not extended by a class; it is implemented by a class.
-
An interface can extend multiple interfaces.
//Creating interface that has 4 methods interface A{ void a();//bydefault, public and abstract void b(); void c(); void d(); } //Creating abstract class that provides the implementation of one method of A interface abstract class B implements A{ public void c(){System.out.println("I am C");} } //Creating subclass of abstract class, now we need to provide the implementation of rest of the methods class M extends B{ public void a(){System.out.println("I am a");} public void b(){System.out.println("I am b");} public void d(){System.out.println("I am d");} } //Creating a test class that calls the methods of A interface class Test5{ public static void main(String args[]){ A a=new M(); a.a(); a.b(); a.c(); a.d(); }} Output: I am a I am b I am c I am d thumb_up 2 thumb_down 1 flag 0

thumb_up 1 thumb_down 0 flag 0

thumb_up 2 thumb_down 0 flag 0

thumb_up 4 thumb_down 1 flag 0
Abinary tree or abst is typically used to store numerical values. The time complexity in a bst is O(log(n)) for insertion, deletion and searching. Each node in a binary tree has at most 2 child nodes.
Trie is an ordered tree structure, which is used mostly for storing strings (like words in dictionary) in acompact way. In a trie, every node (except the root node) stores one character. By traversing up the trie from a leaf node to the root node, a string can be constructed. By traversing down the trie from the root node to a node n, a common prefix can be constructed for all the strings that can be constructed by traversing down all the descendant nodes (including the leaf nodes) of node n.
The following are the main advantages of tries over binary search trees (BSTs):
- Looking up keys is faster. Looking up a key of lengthm takes worst case O(m) time. A BST performs O(log(n)) comparisons of keys, wheren is the number of elements in the tree, because lookups depend on the depth of the tree, which is logarithmic in the number of keys if the tree is balanced. Hence in the worst case, a BST takes O(m logn) time. Moreover, in the worst case log(n) will approachm. Also, the simple operations tries use during lookup, such as array indexing using a character, are fast on real machines.
- Tries are more space efficient when they contain a large number of short keys, because nodes are shared between keys with common initial subsequences.
- Tries facilitate longest-prefix matching, helping to find the key sharing the longest possible prefix of characters all unique.
- The number of internal nodes from root to leaf equals the length of the key. Balancing the tree is therefore no concern.
thumb_up 0 thumb_down 0 flag 0
In the following solution, the variablem refers to minutes, and the variableh to hours.
Let's separate the problem into its components.
- Find the angle of the minute hand from 12 o'clock.
- Find the angle of the hour hand from 12 o'clock.
- Find the absolute value of their difference.
Now, let's start solving each component.
- The minute hand makes a full cycle every hour, or 60 minutes. Therefore, we can get the completed percentage of the cycle of the minute hand by
(m / 60). Since there are 360 degrees, we can get the angle of the minute hand from 12 o'clock by(m / 60) * 360. -
The hour hand makes a full cycle every 12 hours. Since there are 24 hours in a day, we need to normalize the hour value to 12 hours. This is accomplished by
(h % 12), which returns the remainder of the hour value divided by 12.Now, as the minute hand makes its cycle, the hour hand does not just remain at the exact value of
(h % 12). In fact, it moves 30 degrees between(h % 12)and(h % 12) + 1. The amount by which the hour hand deviates from(h % 12)can be calculated by adding to(h % 12)the completed percentage of the cycle of the minute hand, which is(m / 60). Overall, this gives us(h % 12) + (m / 60).Now that we have the exact position of the hour hand, we need to get the completed percentage of the cycle of the hour hand, which we can get by
((h % 12) + (m / 60)) / 12. Since there are 360 degrees, we can get the angle of the hour hand from 12 o'clock by(((h % 12) + (m / 60)) / 12) * 360. -
Now that we have both the angle of the minute and hour hand from 12 o'clock, we simply need to find the difference between the two values, and take the absolute value (since the difference can be negative).
So overall, we have
abs(((((h % 12) + (m / 60)) / 12) - (m / 60)) * 360).
For coding refer : http://www.geeksforgeeks.org/calculate-angle-hour-hand-minute-hand/
thumb_up 0 thumb_down 0 flag 0
LCA algorithm can be found from here :http://www.geeksforgeeks.org/lowest-common-ancestor-binary-tree-set-1/
- Find LCA( least common Ancestor) of 3 pairs - (a, b), (b, c) and (c, a)
- LCA of at-least 2 pairs will be same.
- If all 3 LCAs are same, remove that LCA node.
- If only 2 LCAs are same, then we have two distinct LCA node here. One LCA node will be parent and other LCA node will be child. Remove the Child LCA Node (We may calculate height of the two LCA nodes here. The LCA node with lesser height will be the Child of the other and this lesser height node should be deleted).
In short :
lca of ( a,b) = x;
lca(b,c) = y;
lca(c,a) = z;
atleast two of x,y,x will be same.
if(x==y==z) return any of x,y,z
else return node which is not same as other two.
thumb_up 0 thumb_down 0 flag 0
int Count(int n, int r, int g, int b) { vector<int> fact(n+1); fact[0] = 1; for (int i = 1 ; i <= n ; i++) { fact[i] = fact[i-1]*i; } int remain = n - (r + g + b); int sum = 0; for (int i = 0 ; i <= remain ; i++) { for (int j = 0 ; j <= remain-i ; j++) { int k = remain - (i+j); sum = sum + fact[n] / (fact[i+r]* fact[j+g]*fact[b+k]); } } return sum; } thumb_up 0 thumb_down 0 flag 0
- Create a grid i.e divide the complete area into squares and note the restaurants in the square.
- For any customer in a given square, find out the nearest restaurants by looking up the nearest restaurants in that square and the adjacent squares.
- Can implement grid as 2d array with each element pointing to a linked list containing restaurants.
- Implement a k-element linked list for closest restaurants to customers.
- Can create smaller grids for areas with lot of restaurants with the 2d array pointer pointing to another smaller 2d array which in turn points to restaurants.
thumb_up 1 thumb_down 0 flag 0
The principalnth root![{\sqrt[{n}]{A}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/28c619f2e28fc8407c3489c1b78f2348f129a712)

(for integern there aren distinct complex solutions to this equation if
There is a very fast-converging nth root algorithm for finding
- Make an initial guess
- Set

![x_{k+1}={\frac {1}{n}}\left[{(n-1)x_{k}+{\frac {A}{x_{k}^{n-1}}}}\right]](https://wikimedia.org/api/rest_v1/media/math/render/svg/6a04ab474a1b0d5803206757164ad075abc43707)
In practice we do
![\Delta x_{k}={\frac {1}{n}}\left[{\frac {A}{x_{k}^{n-1}}}-x_{k}\right];x_{k+1}=x_{k}+\Delta x_{k}](https://wikimedia.org/api/rest_v1/media/math/render/svg/034ecc4d0895d2e8452b0c943f8a51e5c0c19587)
- Repeat step 2 until the desired precision is reached, i.e.
.
A special case is the familiar square-root algorithm. By settingn = 2, theiteration rule in step 2 becomes the square root iteration rule:

thumb_up 0 thumb_down 0 flag 0
Consider the situation when (n-1) coins are tossed together and nth coin is tossed apart and take into account mutual independence.
Combine probabilities of simpler cases to get P(1..n, k) (where P(1..n, k) is the probability of obtaining exactly k heads when n coins)
Then apply this rule and fill all the cells in N x K table.
There are two possible ways to get exactly k heads with n coins -
a) if (n-1) coins have k heads, and Nth coin is tail, and
b) if (n-1) coins have k-1 heads, and Nth coin is head
so,
P(n, k) = P(n-1, k) * (1 - p[n]) + P(n-1, k-1) * p[n]
thumb_up 1 thumb_down 0 flag 0
This is just a problem to find the max overlap of segments.
The first reply does not work because it assume everyone come/leave at int hour.
A quick solution is :
1. sort all coming time with leaving time
2. Scan the sorted list, if it is coming, +1, if it is leaving, -1. And record the max number.
That is the answer.
Time Complexity: O(2Nlog(2N))
Space Complexity: O(2N) + sorting space
thumb_up 11 thumb_down 0 flag 0
MAC addresses are the low level basics that make your ethernet based network work.
Network cards each have a unique MAC address. Packets that are sent on the ethernet are always coming from a MAC address and sent to a MAC address. If a network adapter is receiving a packet, it is comparing the packet's destination MAC address to the adapter's own MAC address. If the addresses match, the packet is processed, otherwise it is discarded.
There are special MAC addresses, one for example is ff:ff:ff:ff:ff:ff, which is the broadcast address and addresses every network adapter in the network.
How do IP addresses and MAC addresses work together?
IP is a protocol that is used on a layer above ethernet. Another protocol for example would be IPX.
When your computer wants to send a packet to some IP address x.x.x.x, then the first check is if the destination address is in the same IP network as the computer itself. If x.x.x.x is in the same network, then the destination IP can be reached directly, otherwise the packet needs to be sent to the configured router.
Now we have two IP addresses: one is the original IP packet's target address, the other is the IP of the device to which we should send the packet (the next hop, either the final destination or the router).
Since Ethernet uses MAC addresses, the sender needs to get the MAC address of the next hop. There is a special protocol ARP (address resolution protocol) that is used for that. Once the sender has retrieved the MAC address of the next hop, he writes that target MAC address into the packet and sends the packet.
So, in short
Ip address(network address) is just use for transferring information from one network to an other.travelling of information among networks uses ip addresses.
Mac addresses(physical addresses) is actually uses for distribution of information.
Example:-
Network A , Network B and Network C are three networks.all network are having 5 nodes(client).if i want to send information to node 3 for network B.
Solution:-
1) First send information to network by the help of IP address of that network(Network B).Ip addresses are unique on network layer(this is the fact).
2)After that, send information to node 3 of network B by the help of mac address which is unique at layer 2(Data Link Layer).
thumb_up 32 thumb_down 5 flag 0

thumb_up 23 thumb_down 0 flag 0
1. Cut the cake in quarters (4 pieces) using 2 of the cuts – one horizontally down the center of the cake and the other vertically down the center of the cake.
2. This will leave you with 4 pieces (or slices) of cake. Then, you can take all 4 pieces and arrange them in a stack that is 4 pieces high.
3. Finally, you can just cut that stack of 4 pieces in half – using your third and final cut – and then you will end up with 8 pieces of cake!
thumb_up 12 thumb_down 0 flag 0
There are two possible solutions to this problem.
- Let's start with the easiest solution. If you make one straight horizontal cut along the height of the cake, the resulting slices are of equal sizes. But this solution may not work so well on a cake with icing.
- In general, when a straight cut is made at any angle through the center of a rectangle, the resulting pieces are always of equal area. So let's consider our situation. What if we make a straight cut such that it passes through the center of both the rectangles? Since the cut halves both the rectangles, the resulting two pieces are guaranteed to have equal area. Each piece has an area equal to half the original cake minus half the area of the missing rectangular piece. This results in two pieces of equal size, assuming the cake's height is same at all points.
thumb_up 3 thumb_down 0 flag 0
- In order to align the data in memory, one or more empty bytes (addresses) are inserted (or left empty) between memory addresses which are allocated for other structure members while memory allocation. This concept is called structure padding.
- Architecture of a computer processor is such a way that it can read 1 word (4 byte in 32 bit processor) from memory at a time.
- To make use of this advantage of processor, data are always aligned as 4 bytes package which leads to insert empty addresses between other member's address.
- Because of this structure padding concept in C, size of the structure is always not same as what we think.
For example, please consider below structure that has 5 members.
struct student { int id1; int id2; char a; char b; float percentage; }; - As per C concepts, int and float data types occupy 4 bytes each and char data type occupies 1 byte for 32 bit processor. So, only 14 bytes (4+4+1+1+4) should be allocated for above structure.
- Architecture of a computer processor is such a way that it can read 1 word from memory at a time.
- 1 word is equal to 4 bytes for 32 bit processor and 8 bytes for 64 bit processor. So, 32 bit processor always reads 4 bytes at a time and 64 bit processor always reads 8 bytes at a time.
- This concept is very useful to increase the processor speed.
- To make use of this advantage, memory is arranged as a group of 4 bytes in 32 bit processor and 8 bytes in 64 bit processor.
#include <stdio.h> #include <string.h> /* Below structure1 and structure2 are same. They differ only in member's allignment */ struct structure1 { int id1; int id2; char name; char c; float percentage; }; struct structure2 { int id1; char name; int id2; char c; float percentage; }; int main() { struct structure1 a; struct structure2 b; printf("size of structure1 in bytes : %d\n", sizeof(a)); printf ( "\n Address of id1 = %u", &a.id1 ); printf ( "\n Address of id2 = %u", &a.id2 ); printf ( "\n Address of name = %u", &a.name ); printf ( "\n Address of c = %u", &a.c ); printf ( "\n Address of percentage = %u", &a.percentage ); printf(" \n\nsize of structure2 in bytes : %d\n", sizeof(b)); printf ( "\n Address of id1 = %u", &b.id1 ); printf ( "\n Address of name = %u", &b.name ); printf ( "\n Address of id2 = %u", &b.id2 ); printf ( "\n Address of c = %u", &b.c ); printf ( "\n Address of percentage = %u", &b.percentage ); getchar(); return 0; } OUTPUT: size of structure1 in bytes : 16 Address of id1 = 1297339856 Address of id2 = 1297339860 Address of name = 1297339864 Address of c = 1297339865 Address of percentage = 1297339868 size of structure2 in bytes : 20 Address of id1 = 1297339824 Address of name = 1297339828 Address of id2 = 1297339832 Address of c = 1297339836 Address of percentage = 1297339840 MEMORY ALLOCATION FOR STRUCTURE1:

MEMORY ALLOCATION FOR STRUCTURE2:

HOW TO AVOID STRUCTURE PADDING IN C LANGUAGE?
- #pragma pack ( 1 ) directive can be used for arranging memory for structure members very next to the end of other structure members.
- VC++ supports this feature. But, some compilers such as Turbo C/C++ does not support this feature.
- Please check the below program where there will be no addresses (bytes) left empty because of structure padding.
#include <stdio.h> #include <string.h> /* Below structure1 and structure2 are same. They differ only in member's allignment */ #pragma pack(1) struct structure1 { int id1; int id2; char name; char c; float percentage; }; struct structure2 { int id1; char name; int id2; char c; float percentage; }; int main() { struct structure1 a; struct structure2 b; printf("size of structure1 in bytes : %d\n", sizeof(a)); printf ( "\n Address of id1 = %u", &a.id1 ); printf ( "\n Address of id2 = %u", &a.id2 ); printf ( "\n Address of name = %u", &a.name ); printf ( "\n Address of c = %u", &a.c ); printf ( "\n Address of percentage = %u", &a.percentage ); printf(" \n\nsize of structure2 in bytes : %d\n", sizeof(b)); printf ( "\n Address of id1 = %u", &b.id1 ); printf ( "\n Address of name = %u", &b.name ); printf ( "\n Address of id2 = %u", &b.id2 ); printf ( "\n Address of c = %u", &b.c ); printf ( "\n Address of percentage = %u", &b.percentage ); getchar(); return 0; } thumb_up 4 thumb_down 0 flag 0
- Fault-tolerance or graceful degradation is the property that enables a system (often computer-based) to continue operating properly in the event of the failure of (or one or more faults within) some of its components.
- As an example in real life environment, the Transmission Control Protocol (TCP) is designed to allow reliable two-way communication in a packet-switched network, even in the presence of communications links which are imperfect or overloaded.
The basic characteristics of fault tolerance require:
- No single point of failure
- No single point of repair
- Fault isolation to the failing component
- Fault containment to prevent propagation of the failure
- Availability of reversion modes
Two main reasons for the occurrence of a fault :
- Node failure -Hardware or software failure.
- Malicious Error-Caused by unauthorized Access.
Fault Tolerance is needed in order to provide 3 main feature to distributed systems :
- Reliability-Focuses on a continuous service with out any interruptions.
- Availability - Concerned with read readiness of the system.
- Security-Prevents any unauthorized access.
Examples-Patient Monitoring systems, flight control systems, Banking Services etc.
Fault Tolerance Techniques
1) Replication :
- Creating multiple copies or replica of data items and storing them at different sites
- Main idea is to increase the availability so that if a node fails at one site, so data can be accessed from a different site.
- Has its limitation too such as data consistency and degree of replica.
2 ) Check Pointing
- Saving the state of a system when they are in a consistent state and storing it on a stable storage.
- Each such instance when a system is in the stable state is called a check point.
- In case of a failure, system is restored to its previous consistent state.
- Saves useful computation.
thumb_up 6 thumb_down 0 flag 0
SQL Server needs to guarantee the durability of your transactions (once you commit your data it is there even in the event of power loss) and the ability to roll back the data changed from uncommitted transactions. The mechanism that is being utilized is called Write-Ahead Logging (WAL). It simply means that SQL Server needs to write the log records associated with a particular modification before it writes the page to the disk.
This process ensures that no modifications to a database page will be flushed to disk until the associated transaction log records with that modification are written to disk firs to maintain the ACID properties of a transaction.
Basically WAL is useful when : the transaction gets persisted in the log first and when a power outage happens. The data files and data pages can be appropriately rolled forward (in case of committed transactions) or rolled back (in case of failed/rollback transactions) in the event of abrupt shutdown.
thumb_up 0 thumb_down 0 flag 0
Definition: (Multi-valued dependency)
Let R be a relation scheme and let A and B be two sets of attributes in R (i.e. A⊆R and B⊆R).
Then the MVD A →→ B holds on R if for all pairs of tuples t1 and t2 in R such that
t1 [A] = t2 [A],
there exist tuples t3 and t4 (not necessarily distinct) in R such that:
t1 [A] = t2 [A] = t3 [A] = t4 [A]
t3 [B] = t1 [B]
t3 [R-B] = t2 [R-B]
t4 [B] = t2 [B]
t4 [R-B] = t1 [R-B]

The following all follow immediately from the definition of MVD :
1. Functional dependencies are a special case of MVDs. Multivalued dependencies (MVDs) are a generalisation of functional dependencies (FDs), i.e. every FD is an MVD, but the converse is not true. Suppose an FD A→ B holds on a relation R. Then the MVD A →→ Β also holds on R such that the set of values of B that are dependent on each value of A always consists of a single value.
2. For every relation R and (set of) attributes A, A →→ Α holds. (it is a trivial MVD).
3. For every relation R and (set of) attributes A, A →→ R holds (where R stands for all attributes of R). This is also a a trivial MVD.
4. MVDs always come in pairs. If MVD A →→ Β holds on R then the MVD A →→ R–A–B also holds on R.
Definition: An MVD A →→ B on R is trivial if B⊆A or A ∪ B = R (i.e. A ∪ B is all attributes of R). thumb_up 3 thumb_down 0 flag 0
- Cyclomatic complexity is a software metric used to measure the complexity of a program. These metric, measures independent paths through program source code.
- Independent path is defined as a path that has at least one edge which has not been traversed before in any other paths.
- Cyclomatic complexity can be calculated with respect to functions, modules, methods or classes within a program.
In the graph, Nodes represent processing tasks while edges represent control flow between the nodes.

Flow graph notation for a program:
Flow Graph notation for a program is defines. several nodes connected through the edges. Below are Flow diagrams for statements like if-else, While, until and normal sequence of flow.

Mathematical representation:
Mathematically, it is set of independent paths through the graph diagram. The complexity of the program can be defined as -
V(G) = E - N + 2
Where,
E - Number of edges
N - Number of Nodes
V (G) = P + 1
Where P = Number of predicate nodes (node that contains condition)
Example -

Computing mathematically,
- V(G) = 9 - 7 + 2 = 4
- V(G) = 3 + 1 = 4 (Condition nodes are 1,2 and 3 nodes)
- Basis Set - A set of possible execution path of a program : (1, 7) , (1, 2, 6, 1, 7) , (1, 2, 3, 4, 5, 2, 6, 1, 7) , (1, 2, 3, 5, 2, 6, 1, 7)
Properties of Cyclomatic complexity:
- V (G) is the maximum number of independent paths in the graph
- V (G) >=1
- G will have one path if V (G) = 1
- Minimize complexity to 10
thumb_up 7 thumb_down 0 flag 0

thumb_up 0 thumb_down 0 flag 0
A vtable is created when a class declaration contains a virtual function. A vtable is introduced when a parent -- anywhere in the heirarchy -- has a virtual function, lets call this parent Y. Any parent of Y WILL NOT have a vtable (unless they have avirtual for some other function in their heirarchy).
- When you specify a member function as virtual, there is a chance that you may try to use sub-classes via a base-class polymorphically at run-time.
- To maintain c++'s guarantee of performance over language design they offered the lightest possible implementation strategy -- i.e., one level of indirection, and only when a class might be used polymorphically at runtime, and the programmer specifies this by setting at least one function to be virtual.
- Only when a base class contains a virtual function do any other sub-classes contain a vtable. The parents of said base class do not have a vtable.
#include <iostream> class test_base { public: void x(){std::cout << "test_base" << "\n"; }; }; class test_sub : public test_base { public: virtual void x(){std::cout << "test_sub" << "\n"; } ; }; class test_subby : public test_sub { public: void x() { std::cout << "test_subby" << "\n"; } }; int main() { test_sub sub; test_base base; test_subby subby; test_sub * psub; test_base *pbase; test_subby * psubby; pbase = ⊂ pbase->x(); psub = &subby; psub->x(); return 0; } output
test_base test_subby test_basedoes not have a virtual table therefore anything casted to it will use thex() from test_base .
test_subon the other hand changes the nature ofx() and its pointer will indirect through a vtable, and this is shown by test_ subby's x() being executed.
So, a vtable is only introduced in the hierarchy when the keyword virtual is used. Older ancestors do not have a vtable, and if a downcast occurs it will be hardwired to the ancestors functions.
thumb_up 0 thumb_down 0 flag 0
Method 1:
SQL > DELETE FROM table_name A WHERE ROWID > ( SELECT min(rowid) FROM table_name B WHERE A.key_values = B.key_values); Delete all rowids that is BIGGER than the SMALLEST rowid value (for a given key).
Method 2:
SQL> create table table_name2 as select distinct * from table_name1; SQL> drop table table_name1; SQL> rename table_name2 to table_name1; This method is usually faster. However, remember to recreate all indexes, constraints, triggers, etc. on the table when done.
Method 3:
SQL> delete from my_table t1 SQL> where exists (select 'x' from my_table t2 SQL> where t2.key_value1 = t1.key_value1 SQL> and t2.key_value2 = t1.key_value2 SQL> and t2.rowid > t1.rowid); thumb_up 2 thumb_down 0 flag 0
IS-A Relationship:
In object-oriented programming, the concept of IS-A is a totally based on Inheritance, which can be of two types Class Inheritance or Interface Inheritance.
For example, Apple is a Fruit, Car is a Vehicle etc.
Inheritance is unidirectional.
For example, House is a Building. But Building is not a House.
It is a key point to note that you can easily identify the IS-A relationship. Wherever you see an extends keyword or implements keyword in a class declaration, then this class is said to have IS-A relationship.
HAS-A Relationship:
Composition (HAS-A) simply mean the use of instance variables that are references to other objects.
For example,Maruti has Engine, or House has Bathroom.

class Car { // Methods implementation and class/Instance members private String color; private int maxSpeed; public void carInfo(){ System.out.println("Car Color= "+color + " Max Speed= " + maxSpeed); } public void setColor(String color) { this.color = color; } public void setMaxSpeed(int maxSpeed) { this.maxSpeed = maxSpeed; } } As shown above, Car class has a couple of instance variable and few methods. Maruti is a specific type of Car which extends Car class means Maruti IS-A Car.
class Maruti extends Car{ //Maruti extends Car and thus inherits all methods from Car (except final and static) //Maruti can also define all its specific functionality public void MarutiStartDemo(){ Engine MarutiEngine = new Engine(); MarutiEngine.start(); } } Maruti class uses Engine object's start() method via composition. We can say that Maruti class HAS-A Engine.
public class Engine { public void start(){ System.out.println("Engine Started:"); } public void stop(){ System.out.println("Engine Stopped:"); } } RelationsDemo class is making object of Maruti class and initialized it. Though Maruti class does not have setColor(), setMaxSpeed() and carInfo() methods still we can use it due to IS-A relationship of Maruti class with Car class.
public class RelationsDemo { public static void main(String[] args) { Maruti myMaruti = new Maruti(); myMaruti.setColor("RED"); myMaruti.setMaxSpeed(180); myMaruti.carInfo(); myMaruti.MarutiStartDemo(); } } Summary
- IS-A relationship based on Inheritance, which can be of two types Class Inheritance or Interface Inheritance.
- Has-a relationship is composition relationship which is a productive way of code reuse.
thumb_up 1 thumb_down 0 flag 0
Fail-Fast Iterators
- Fail-Fast iterators doesn't allow modifications of a collection while iterating over it.
- These iterators throwConcurrentModificationException if a collection is modified while iterating over it.
- They use original collection to traverse over the elements of the collection.
- These iterators don't require extra memory.
- Ex : Iterators returned byArrayList,Vector,HashMap.
Fail-Safe Iterators
- Fail-Safe iterators allow modifications of a collection while iterating over it.
- These iterators don't throw any exceptions if a collection is modified while iterating over it.
- They use copy of the original collection to traverse over the elements of the collection.
- These iterators require extra memory to clone the collection.
- Ex : Iterator returned byConcurrentHashMap.
How Fail-Fast Iterators Work?
- All Collection types maintain an internal array of objects ( Object[] ) to store the elements.Fail-Fast iterators directly fetch the elements from this array.
- They always consider that this internal array is not modified while iterating over its elements.
- To know whether the collection is modified or not, they use an internal flag calledmodCount which is updated each time a collection is modified.
- Every time when an Iterator calls thenext() method, it checks themodCount. If it finds themodCounthas been updated after this Iterator has been created, it throwsConcurrentModificationException.
import java.util.ArrayList; import java.util.Iterator; public class FailFastIteratorExample { public static void main(String[] args) { //Creating an ArrayList of integers ArrayList<Integer> list = new ArrayList<Integer>(); //Adding elements to list list.add(1452); list.add(6854); list.add(8741); list.add(6542); list.add(3845); //Getting an Iterator from list Iterator<Integer> it = list.iterator(); while (it.hasNext()) { Integer integer = (Integer) it.next(); list.add(8457); //This will throw ConcurrentModificationException } } } Output :
Exception in thread "main" java.util.ConcurrentModificationException at java.util.ArrayList$Itr.checkForComodification(Unknown Source) at java.util.ArrayList$Itr.next(Unknown Source) at pack1.MainClass.main(MainClass.java:32) How Fail-Safe Iterators Work?
import java.util.Iterator; import java.util.concurrent.ConcurrentHashMap; public class FailSafeIteratorExample { public static void main(String[] args) { //Creating a ConcurrentHashMap ConcurrentHashMap<String, Integer> map = new ConcurrentHashMap<String, Integer>(); //Adding elements to map map.put("ONE", 1); map.put("TWO", 2); map.put("THREE", 3); map.put("FOUR", 4); //Getting an Iterator from map Iterator<String> it = map.keySet().iterator(); while (it.hasNext()) { String key = (String) it.next(); System.out.println(key+" : "+map.get(key)); map.put("FIVE", 5); //This will not be reflected in the Iterator } } } Output :
TWO : 2 FOUR : 4 ONE : 1 THREE : 3 thumb_up 3 thumb_down 0 flag 0
yield() method
A yielding thread tells the virtual machine that it's willing to let other threads be scheduled in its place. This indicates that it's not doing something too critical.
yield() is defined as following in Thread.java.
/** * A hint to the scheduler that the current thread is willing to yield its current use of a processor. The scheduler is free to ignore * this hint. Yield is a heuristic attempt to improve relative progression between threads that would otherwise over-utilize a CPU. * Its use should be combined with detailed profiling and benchmarking to ensure that it actually has the desired effect. */ public static native void yield(); yield() method example usage :
In below example program, I have created two threads named producer and consumer. Producer is set to minimum priority and consumer is set to maximum priority. I will run below code with/without commenting the line Thread.yield().
- Without yield(), though the output changes sometimes, but usually first all consumer lines are printed and then all producer lines.
- With using yield() method, both prints one line at a time and pass the chance to another thread, almost all the time.
public class YieldExample { public static void main(String[] args) { Thread producer = new Producer(); Thread consumer = new Consumer(); producer.setPriority(Thread.MIN_PRIORITY); //Min Priority consumer.setPriority(Thread.MAX_PRIORITY); //Max Priority producer.start(); consumer.start(); } } class Producer extends Thread { public void run() { for (int i = 0; i < 5; i++) { System.out.println("I am Producer : Produced Item " + i); Thread.yield(); } } } class Consumer extends Thread { public void run() { for (int i = 0; i < 5; i++) { System.out.println("I am Consumer : Consumed Item " + i); Thread.yield(); } } } Output of above program "without" yield() method :
I am Consumer : Consumed Item 0 I am Consumer : Consumed Item 1 I am Consumer : Consumed Item 2 I am Consumer : Consumed Item 3 I am Consumer : Consumed Item 4 I am Producer : Produced Item 0 I am Producer : Produced Item 1 I am Producer : Produced Item 2 I am Producer : Produced Item 3 I am Producer : Produced Item 4 Output of above program "with" yield() method added :
I am Producer : Produced Item 0 I am Consumer : Consumed Item 0 I am Producer : Produced Item 1 I am Consumer : Consumed Item 1 I am Producer : Produced Item 2 I am Consumer : Consumed Item 2 I am Producer : Produced Item 3 I am Consumer : Consumed Item 3 I am Producer : Produced Item 4 I am Consumer : Consumed Item 4 join() method
The join() method of a Thread instance can beused to "join" the start of a thread's execution to the end of another thread's execution so that a thread will not start running until another thread has ended. If join() is called on a Thread instance, the currently running thread will block until the Thread instance has finished executing.
//Waits for this thread to die. public final void join() throws InterruptedException Like sleep, join responds to an interrupt by exiting with an InterruptedException.
join() method example usage :
public class JoinExample { public static void main(String[] args) throws InterruptedException { Thread t = new Thread(new Runnable() { public void run() { System.out.println("First task started"); System.out.println("Sleeping for 2 seconds"); try { Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("First task completed"); } }); Thread t1 = new Thread(new Runnable() { public void run() { System.out.println("Second task completed"); } }); t.start(); // Line 15 t.join(); // Line 16 t1.start(); } } Output :
First task started Sleeping for 2 seconds First task completed Second task completed thumb_up 1 thumb_down 0 flag 0
public class HelloJava{ public static void main(String args[]){ System.out.println("Helloworld in Java"); } } String args[], which is actually anarray of java.lang.String type, and it's name isargs here. It's not necessary to name it args always, you can name it strArray or whatever you like. When we run a Java program from command prompt, we can pass some input to our Java program. Those inputs are stored in this String args array. For example if we modify our program to print content of String args[], as shown below:
public class StringArgsTest { public static void main(String args[]) { System.out.println("String arguments passed while running this Java Program : "); for(String argument : args){ System.out.println(argument); } } } and after compiling, we run this Java program as
javaStringArgsTest Java J2EE Android
then this program will print following output :
String arguments passed while running this Java Program : Java J2EE Android because, we have passed three arguments separated by white space. If you want to combine multiple words, which has some white space in between, then you can enclose them in double quotes.
thumb_up 2 thumb_down 0 flag 0
Java program'smain method has to be declaredstatic because keywordstatic allows main to be called without creating an object of the class in which themainmethod is defined. If we omit statickeyword beforemain Java program will successfully compile but it won't execute.
public static void main (String[] args) - The
publickeyword is an access specifier, which allows the programmer to control the visibility of class members. When a class member is preceded bypublic, then that member may be accessed by code outside the class in which it is declared. In this case,mainmust be declared aspublic, since it must be called by code outside of its class when the program is started. - The keyword
staticallowsmainto be called without having to instantiate a particular instance of the class. Without having declaredmainmethodstatic, your program will successfully compile but won't execute and report error at run time. This is necessary sincemainis called by the Java interpreter before any objects are made. - The keyword
voidsimply tells the compiler thatmaindoes not return a value. Themainis the method called when a Java application begins.
Java is case-sensitive. Thus,Main is different frommain. It is important to understand that the Java compiler will compile classes that do not contain amain method. But the Java interpreter has no way to run these classes. So, if you had typedMain instead ofmain, the compiler would still compile your program. However, the Java interpreter would report an error because it would be unable to find themain method.
thumb_up 12 thumb_down 1 flag 0
I would give the car keys to my best friend, and let him take the old lady to the hospital. Then I would stay behind and wait for the bus my lover.
thumb_up 5 thumb_down 0 flag 0
The bridge won't break.
When the car has traveled half of the bridge, that is 15km, the car must have used more than 400 grams of fuel. Therefore, the impact of bird's added weight will be zero literally.
thumb_up 6 thumb_down 0 flag 0
Let's take a scenario. Suppose you pick from jar labelled as Apple and Oranges and you got Apple from it. That means that jar should be Apple as it is incorrectly labelled. So it has to be Apple jar.
Now the jar labelled Oranges has to be Mixed as it cannot be the Oranges jar as they are wrongly labelled and the jar labelled Apple has to be Oranges.
Similar scenario applies if it's a Oranges taken out from the jar labelled as Apple and Oranges.
So you need to pick just one fruit from the jar labelled as Apple and Oranges to correctly label the jars.
thumb_up 2 thumb_down 0 flag 0
- I guess the biggest reason is popularity. Most OS's are huge, so lots of team members are needed on working on separate portions of the kernel. So finding enough experts in such languages might be an issue.
-
C has the advantage of being a small language, so developing compilers and cross compilers is relatively easy. So, while it is possible to create OS's in other languages (and it has been done), C is convenient.
-
Processors run binary Machine Code. Assembly is the language that represents Machine Code. Operating System requirements became too arduous to implement purely in Assembly, so a higher level abstraction was required, C is one such abstraction. C is a very popular language which can directly generate Machine Code, without requiring you to write the entire OS in Assembly.
-
Compiled C does not require a runtime, the compiler generates Machine Code. There are C libraries, not quite the same as a runtime, but those are for higher level functionality. If those dependencies are avoided, as they are in the core of an OS, then no runtime libraries are required.
thumb_up 6 thumb_down 0 flag 0
Foreign key definitions says its states the relationship of one attribute(Column) of one table to the corresponding column on the other table.
So one as a parent and other is child. PARENT is that table which holds the primary key and CHILD is table which holds the referential key. Hence every entry in the PRIMARY table is unique where as same entry might be repeating in the child table. BUT that same has to be present in the PARENT table (Primary KEY).
By definition Foreign key can be of two types :
1.ON DELETE SET NULL
2.ON DELETE SET CASCADE
a) On delete set null :
When a foreign key is created by on delete set null definition then when you delete one row from the primary column (of parent table ) , then the corresponding entry in the foreign key table (Child table ) have the value "NULL" for that particular column.
b) ON Delete Set Cascade:
When the foreign key is created by this definition then when you delete the primary column (any one row -unique data) , then the Child table forcefully deletes all the rows in the child table having same value for that particular column.
Basically foreign key used to make a relation ship between the tables, used to reduce the redundancy of data and data integrity.
thumb_up 4 thumb_down 0 flag 0
1) Remove Spyware :
- Spyware can cause pop-ups as well as collect personal information without letting you know or asking for permission. This puts your computer and your information at risk.
- Make sure you use a reputable spyware remover to take care of the problem.
2) Free Up Disk Space :The Disk Cleanup tool is a great way to help free up space on your hard disk and improve performance. A few things Dick Cleanup can do are:
- Remove temporary internet files (which generally take up the most space).
- Empty the Recycle Bin.
- Delete programs you never use.
- Remove Windows Temporary files, such as error reports.
- Backup files you never access.
3) Use ReadyBoost
- This tool basically uses a USB flash drive or memory card to introduce a level of memory that functions somewhere between RAM and your hard drive disk for storing non-volatile memory.
- ReadyBoost works better on systems that struggle to open and maintain the speed of certain programs.
- It will enhance your computer, but only if you have a hard drive that is at capacity or a system that is several years old. Otherwise, you are not going to notice much of a difference.
4) Add RAM
- More RAM means a faster feel to opening files and easier multitasking.
- For every program you open, your computer uses RAM; if you have multiple programs open at once and lack sufficient memory, everything will slow down.
- Upgrading RAM is fairly inexpensive these days, and it can drastically help your computer.
5) Remove junk
- Automatic update systems for various applications (but be careful: some apps, like Flash, Acrobat, QuickTime, and Web browsers are prime malware targets and you will want to keep these up-to-date)
- Things that run on startup
- Windows services you don't really need
- Toolbars
- Browser plug-ins (the Skype browser plug-in is an especially bad offender, I've found)
- P2P applications
For more knowledge regarding the same, please read the article : http://www.techrepublic.com/blog/10-things/10-things-you-can-do-to-boost-pc-performance/
thumb_up 4 thumb_down 0 flag 0
The MySQL trigger is a database object that is associated with a table. It will be activated when a defined action is executed for the table. The trigger can be executed when you run one of the following MySQL statements on the table: INSERT, UPDATE and DELETE. It can be invoked before or after the event.
Benefits of Triggers :
Triggers can be written for the following purposes −
- Generating some derived column values automatically
- Enforcing referential integrity
- Event logging and storing information on table access
- Auditing
- Synchronous replication of tables
- Imposing security authorizations
- Preventing invalid transactions
The syntax for creating a trigger is −
CREATE [OR REPLACE ] TRIGGER trigger_name {BEFORE | AFTER | INSTEAD OF } {INSERT [OR] | UPDATE [OR] | DELETE} [OF col_name] ON table_name [REFERENCING OLD AS o NEW AS n] [FOR EACH ROW] WHEN (condition) DECLARE Declaration-statements BEGIN Executable-statements EXCEPTION Exception-handling-statements END; Where,
-
CREATE [OR REPLACE] TRIGGER trigger_name − Creates or replaces an existing trigger with thetrigger_name.
-
{BEFORE | AFTER | INSTEAD OF} − This specifies when the trigger will be executed. The INSTEAD OF clause is used for creating trigger on a view.
-
{INSERT [OR] | UPDATE [OR] | DELETE} − This specifies the DML operation.
-
[OF col_name] − This specifies the column name that will be updated.
-
[ON table_name] − This specifies the name of the table associated with the trigger.
-
[REFERENCING OLD AS o NEW AS n] − This allows you to refer new and old values for various DML statements, such as INSERT, UPDATE, and DELETE.
-
[FOR EACH ROW] − This specifies a row-level trigger, i.e., the trigger will be executed for each row being affected. Otherwise the trigger will execute just once when the SQL statement is executed, which is called a table level trigger.
-
WHEN (condition) − This provides a condition for rows for which the trigger would fire. This clause is valid only for row-level triggers.
Here is an example of a MySQL trigger :
1) First we will create the table for which the trigger will be set:
mysql> CREATE TABLE people (age INT, name varchar(150));
2) Next we will define the trigger. It will be executed before every INSERT statement for the people table:
mysql> delimiter //
mysql> CREATE TRIGGER agecheck BEFORE INSERT ON people FOR EACH ROW IF NEW.age < 0 THEN SET NEW.age = 0; END IF;//
Query OK, 0 rows affected (0.00 sec)
mysql> delimiter ;
3) We will insert two records to check the trigger functionality.
mysql> INSERT INTO people VALUES (-20, 'Sid'), (30, 'Josh');
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0
4) At the end we will check the result (age < 0, it is converted to 0 in case of name = "Sid")
mysql> SELECT * FROM people;
+——-+——-+
| age | name |
+——-+——-+
| 0 | Sid |
| 30 | Josh |
+——-+——-+
thumb_up 7 thumb_down 0 flag 0
Both vector and list are sequential containers of C++ Standard Template Library. But there are many differences between them because of their internal implementation i.e.
List stores elements at non contiguous memory location i.e. it internally uses a doubly linked list i.e.

Whereas,vector stores elements at contiguous memory locations like an array i.e.

1) Insertion and Deletion
Insertion and Deletion in List is very efficient as compared to vector because to insert an element in list at start, end or middle, internally just a couple of pointers are swapped.
Whereas, in vector insertion and deletion at start or middle will make all elements to shift by one. Also, if there is insufficient contiguous memory in vector at the time of insertion, then a new contiguous memory will be allocated and all elements will be copied there.
So, insertion and deletion in list is much efficient than vector in c++.
2) Random Access:
As List is internally implemented as doubly linked list, therefore no random access is possible in List. It means, to access 15th element in list we need to iterate through first 14 elements in list one by one.
Whereas, vector stores elements at contiguous memory locations like an array. Therefore, in vector random access is possible i.e. we can directly access the 15th element in vector using operator [] i.e.
std::vector<int> vec(20); vec[15] = 10; So, we can not use std::list with some of the STL algorithm that needs the random access operators like std::sort.
3) Sort
The next operation that is tested is the performance of sorting a vector or a list. For a vector std::sort is used and for a list the member function sort is used. Sorting a list is several times slower. It comes from the poor usage of the cache.
These are the simple conclusions on usage of each data structure:
- For linear search: use std::vector
- ForRandom Insert/Remove: use std::list (if data size very small then use std::vector)
- Forbig data size: use std::list (not if intended for searching)
thumb_up 8 thumb_down 0 flag 0
An object copy is a process where a data object has its attributes copied to another object of the same data type.
Shallow Copy :
- Shallow copying is creating a new object and then copying the non static fields of the current object to the new object. If the field is a value type, a bit by bit copy of the field is performed. If the field is a reference type, the reference is copied but the referred object is not, therefore the original object and its clone refer to the same object. A shallow copy of an object is a new object whose instance variables are identical to the old object.
- The situations like , if you have an object with values and you want to create a copy of that object in another variable from same type, then you can use shallow copy, all property values which are of value types will be copied, but if you have a property which is of reference type then this instance will not be copied, instead you will have a reference to that instance only.
- A shallow copy can be made by simply copying the reference.
public class Ex { private int[] data; // makes a shallow copy of values public Ex(int[] values) { data = values; } public void showData() { System.out.println( Arrays.toString(data) ); } } public class UsesEx{ public static void main(String[] args) { int[] vals = {-5, 12, 0}; Ex e = new Ex(vals); e.showData(); // prints out [-5, 12, 0] vals[0] = 13; e.showData(); // prints out [13, 12, 0] // Very confusing, because I didn't intentionally change anything about the // object e refers to. } } 
Deep Copy :
- Deep copy is creating a new object and then copying the non-static fields of the current object to the new object. If a field is a value type, a bit by bit copy of the field is performed. If a field is a reference type, a new copy of the referred object is performed. A deep copy of an object is a new object with entirely new instance variables, it does not share objects with the old.
- A deep copy means actually creating a new array and copying over the values.
public class Ex{ private int[] data; // altered to make a deep copy of values public Ex(int[] values) { data = new int[values.length]; for (int i = 0; i < data.length; i++) { data[i] = values[i]; } } public void showData() { System.out.println(Arrays.toString(data)); } } public class UsesEx{ public static void main(String[] args) { int[] vals = {-5, 12, 0}; Ex e = new Ex(vals); e.showData(); // prints out [-5, 12, 0] vals[0] = 13; e.showData(); // prints out [13, 12, 0] // Very confusing, because I didn't intentionally change anything about the // object e refers to. } } 
thumb_up 8 thumb_down 1 flag 0

thumb_up 0 thumb_down 0 flag 0
Product :
- Product is like 'ready to use solution' which is built by the company and sold to different customers (or) setup as free source.If customer requires any changes like color, title, appearance changes and some extra functionality to be added, then customization's are done to the product.
- Product is a company that releases Hardware, Middleware, Operating system, Languages, Tools etc are becomes the product. They develop the products for global clients i.e. there are no specific clients for them. Here the requirements are gathered from market and analyze that with some experts and start to develop the product. After developing the products they try to market it as a solution. Here the end users are more than one. Product development is never ending process and customization is possible.
General e.g.: Purchasing a flat after construction is completed – In this case You can only do minor changes like paints and interiors.
Examples: Google products like Gmail, Drive (Free sources) and Oracle products like Databases etc, Warehouse Management systems of Manhattan, SAP, Red Prairie and JDA (Paid products).
Project :
- Project is 'taking requirements from customer to build a solution'. The requirements are gathered from a particular client.
- Project is finding solution to a particular problem to a particular client. It depends on the product. By using the products like Hardware, Middleware, Operating system, Languages and Tools only we will develop a project. Here the requirements are gathered from the client and analyze with that client and start to develop the project. Here the end user is one.
General e.g.: Purchasing a flat before construction. You can construct it as per your guidelines and requirement.
Examples: Banking projects like ICICI, HDFC and e-commerce projects like flipkart.com and bigbasket.com. These are specific to clients.
thumb_up 6 thumb_down 0 flag 0
2nd highest score in MySQL with subquery :
SELECT id, max(score) FROM employees
WHERE score < (SELECT max(score) FROM employees)
2nd highest score in MySQL without subquery :
SELECT salary FROM employees ORDER BY salary DESC LIMIT 1,1
thumb_up 7 thumb_down 0 flag 0
- Ifn = 1, there isone 1-by-1 square.
- Ifn = 2, there isone 2-by-2 square andfour 1-by-1 squares.
- Ifn = 3, there isone 3-by-3 square,four 2-by-2 squares andnine 1-by-1 squares.
If we continued the above sequence for an arbitraryn, then we would haveone ( n-by-n) square,four (n - 1)-by-(n - 1) squares,nine (n - 2)-by-(n - 2) squares, ... , and n^2 (1-by-1) squares.
Notice that this is just the summation:

so, for 4 X 4 squares , total number of squares are : (4*5*9) / 6 = 30
thumb_up 0 thumb_down 6 flag 0
Since it is hot, people will take more bath.
thumb_up 17 thumb_down 0 flag 0
As given in the question , the gold bar is segmented into seven connected pieces.

Lets split the chain as,

Day 1: Give A (+1)
Day 2: Get back A, give B (-1, +2)
Day 3: Give A (+1)
Day 4:Get back A and B, give C (-2,-1,+4)
Day 5:Give A (+1)
Day 6:Get back A, give B (-1,+2)
Day 7:Give A (+1)
Hence, only 2 cuts are required.
thumb_up 0 thumb_down 0 flag 0
Software Testing Life Cycle (STLC) is defined as a sequence of activities conducted to perform Software Testing. It consists of series of activities carried out methodologically to help certify your software product.

- Requirements/ Design Review : You review the software requirements/ design (if they exists).
- Test Planning : Once you have gathered a general idea of what needs to be tested, you 'plan' for the tests.
- Test Designing : You design/ detail your tests on the basis of detailed requirements/design of the software.
- Test Environment Setup : You setup the test environment (server/ client/ network, etc) with the goal of replicating the end-users' environment.
- Test Execution : You execute your Test Cases/ Scripts in the Test Environment to see whether they pass.
- Test Reporting : You prepare various reports for various stakeholders.
thumb_up 0 thumb_down 0 flag 0
A software process model is an abstract representation of a process. It presents a description of a process from some particular perspective as:
1. Specification.
2. Design.
3. Validation.
4. Evolution.
General Software Process Models are
1. Waterfall model : Waterfall model is the simplest model of software development paradigm. It says the all the phases of SDLC ( Software Development Life Cycle) will function one after another in linear manner. That is, when the first phase is finished then only the second phase will start and so on.
2. V-Model : The major drawback of waterfall model is we move to the next stage only when the previous one is finished and there was no chance to go back if something is found wrong in later stages. V-Model provides means of testing of software at each stage in reverse manner.
3. Rapid application development model (RAD).
4. Incremental model.
5. Iterative model : This model leads the software development process in iterations. It projects the process of development in cyclic manner repeating every step after every cycle of SDLC process.
6. Spiral model :Spiral model is a combination of both, iterative model and one of the SDLC model. It can be seen as if you choose one SDLC model and combine it with cyclic process (iterative model).
For further detailed explanation, please follow the the references : https://melsatar.wordpress.com/2012/03/15/software-development-life-cycle-models-and-methodologies/
thumb_up 2 thumb_down 0 flag 0
A servlet life cycle can be defined as the entire process from its creation till the destruction. The following are the paths followed by a servlet
-
The servlet is initialized by calling theinit () method.
-
The servlet callsservice() method to process a client's request.
-
The servlet is terminated by calling thedestroy() method.
-
Finally, servlet is garbage collected by the garbage collector of the JVM.

The init() method :
The init method is designed to be called only once. It is called when the servlet is first created, and not called again for each user request. So, it is used for one-time initializations, just as with the init method of applets. It is the life cycle method of the javax.servlet.Servlet interface. Syntax of the init method is given below :
public void init(ServletConfig config) throws ServletException The service() method :
The service() method is the main method to perform the actual task. The servlet container (i.e. web server) calls the service() method to handle requests coming from the client( browsers) and to write the formatted response back to the client.
Each time the server receives a request for a servlet, the server spawns a new thread and calls service. The service() method checks the HTTP request type (GET, POST, PUT, DELETE, etc.) and calls doGet, doPost, doPut, doDelete, etc. methods as appropriate. The syntax of the service method of the Servlet interface is given below :
public void service(ServletRequest request, ServletResponse response) throws ServletException, IOException The destroy() method :
The destroy() method is called only once at the end of the life cycle of a servlet. This method gives your servlet a chance to close database connections, halt background threads, write cookie lists or hit counts to disk, and perform other such cleanup activities. The syntax of the destroy method of the Servlet interface is given below :
public void destroy() thumb_up 2 thumb_down 0 flag 0
Compilation and execution of a Java program is two step process :
- During compilation phase Java compiler compiles the source code and generates bytecode. This intermediate bytecode is saved in form of a .class file.
- In second phase, Java virtual machine (JVM) also called Java interpreter takes the .class as input and generates output by executing the bytecode. Java is an object oriented programming language; therefore, a program in Java is made of one or more classes. No matter how trivial a Java program is, it must be written in form of a class.
Develop Java Program
To demonstrate compilation and execution of a Java program we create a simple HelloWorld program.
- While writing HelloWorld program we must keep in mind that the file name and the name of the class that contains main method must be identical.
- Second, a file can contain only one public class at a time therefore, if a file contains more than one class, the only class can be declared public at a time. By keeping above rules in mind we create a Java program HelloWorld.java inserting the following piece of code into a plain text file.
/* HelloWorld.java */ class HelloWorld { public static void main(String[] args) { // prints Hello World! on console System.out.println("Hello World!"); } } Compile Java Program From Command Prompt
Once the Java program is written and saved, first, it has to be compiled. To compile a Java program from command line we need to invoke the Java compiler by supplying javac command. Java compiler comes with JDK (Java Development Kit). JDK is a bundle of software needed for developing Java applications. It includes the JRE (Java Runtime Environment), set of API classes, Java compiler, Webstart and additional files needed to write Java applets and applications.
Now, compile HelloWorld.java as follows:
javac HelloWorld.java
The javac compiler creates a file called HelloWorld.class that contains the bytecode version of the program. As said earlier, the Java bytecode is the intermediate representation of HelloWorld.java program that contains instructions the Java interpreter will execute. The Java compiler doesn't execute the Java program - that is the job of the Java virtual machine. However, the Java virtual machine cannot execute .java files directly. The compiler's job is to translate Java source files into "class files" that the virtual machine can execute.
Note that the Java compiler (javac) also facilitates to compile multiple .java files together. If there are more than one Java source files in the same directory, you can either list the file names separated by spaces, or use the wildcard characters, for example,
javac HelloWorld.java one.java two.java
Run Java Program From Command Prompt
After successful compilation of HelloWorld.java to HelloWorld.class to actually run the program, we use the Java interpreter, called java. To do so, pass the class name HelloWorld as a command-line argument, as shown follows:
java HelloWorld
The message Hello World! will be printed on the screen as a result of the above command.
thumb_up 19 thumb_down 2 flag 0
Real life examples of queue are:
- A queue of people at ticket-window: The person who comes first gets the ticket first. The person who is coming last is getting the tickets in last. Therefore, it follows first-in-first-out (FIFO) strategy of queue.
- Vehicles on toll-tax bridge: The vehicle that comes first to the toll tax booth leaves the booth first. The vehicle that comes last leaves last. Therefore, it follows first-in-first-out (FIFO) strategy of queue.
- Phone answering system: The person who calls first gets a response first from the phone answering system. The person who calls last gets the response last. Therefore, it follows first-in-first-out (FIFO) strategy of queue.
- Luggage checking machine: Luggage checking machine checks the luggage first that comes first. Therefore, it follows FIFO principle of queue.
- Patients waiting outside the doctor's clinic: The patient who comes first visits the doctor first, and the patient who comes last visits the doctor last. Therefore, it follows the first-in-first-out (FIFO) strategy of queue.
Real life examples of stack are:
- To reverse a word . You push a given word to stack - letter by letter - and then pop letters from the stack.
- An "undo" mechanism in text editors; this operation is accomplished by keeping all text changes in a stack.
- Undo/Redostacks in Excel or Word.
- Language processing :
- space for parameters and local variables is created internally using a stack.
- compiler's syntax check for matching braces is implemented by using stack.
- A stack of plates/books in a cupboard.
- Wearing/Removing Bangles .
- Support for recursion
- Activation records of method calls.
thumb_up 0 thumb_down 0 flag 0
a) Cross-site scripting
Definition: When a hacker sends commands embedded in queries to a website.
Problem: A hacker types JavaScript into any text field, such as a change-of-address field. When a legitimate user types information into that field, the JavaScript is activated, which allows the hacker to take control of the session and grants him all the user's session rights, enabling him to move money or steal credit card numbers.
What you can do: Make sure every text field will accept only those characters and length of characters that are suitable for that field--for example, five numbers in a ZIP code field and five numbers only.
b) Denial of Service
Definition: Sending thousands of queries to a Web server to overload the system, slowing it down or causing it to crash.
Problem: While not an attack meant to steal personal information, the attack is meant to be purely malicious by slowing down a business's online services and commerce.
What you can do: Require users to log on to your site so that you process queries only from legitimate users. Limit the number of queries within a certain time frame per user. After three log-in failures, lock out the user for a certain amount of time to thwart a DNS attack on the log-in app.
c) SQL injection
Read about SQL injection from this link : http://www.geeksforgeeks.org/basic-sql-injection-mitigation-example/
d)Unvalidated inputs
Definition: Not checking whether text a user types into a field on a website is appropriate for that field.
Problem: Hackers use these fields to type commands that allow them to scan for vulnerabilities and gain access.
What you can do: Validate that each field accepts only those characters that are common for that field (such as numbers for a post code field) and are an appropriate length. Run the inputs against a small library of post codes and addresses to confirm that the information is valid.
thumb_up 5 thumb_down 0 flag 0
1) State Information :
- A Stateful server remember client data (state) from one request to the next. Stateful servers, do store session state. They may, therefore, keep track of which clients have opened which files, current read and write pointers for files, which files have been locked by which clients, etc.
- A Stateless server keeps no state information.Stateless file servers do not store any session state. This means that every client request is treated independently, and not as a part of a new or existing session.
2) Programming :
- Stateful server is harder to code.
- Stateless server is straightforward to code.
3) Crash recovery :
- Stateful servers have difficult crash recovery due to loss of information.
- Stateless servers can easily recover from failure because there is no state that must be restored.
4) Information transfer :
- Using a Stateful server,file server, the client can send less data with each request.
- Using a stateless file server, the client must,specify complete file names in each request specify location for reading or writing re-authenticate for each request.
Advantages of both Stateful and Stateless servers:
The main advantage of Stateful servers, is that they can provide better performance for clients because clients do not have to provide full file information every time they perform an operation, the size of messages to and from the server can be significantly decreased. Likewise the server can make use of knowledge of access patterns to perform read-ahead and do other optimizations. Stateful servers can also offer clients extra services such as file locking, and remember read and write positions.
The main advantage of stateless servers is that they can easily recover from failure. Because there is no state that must be restored, a failed server can simply restart after a crash and immediately provide services to clients as though nothing happened. Furthermore, if clients crash the server is not stuck with abandoned opened or locked files. Another benefit is that the server implementation remains simple because it does not have to implement the state accounting associated with opening, closing, and locking of files.
thumb_up 0 thumb_down 0 flag 0
- "Agile Development" is an umbrella term for several iterative and incremental software development methodologies. Agile development is a phrase used to describe methodologies for incremental software development.
- The most popular agile methodologies include Extreme Programming (XP), Scrum, Crystal, Dynamic Systems Development Method (DSDM), Lean Development, and Feature-Driven Development (FDD).
- While each of the agile methodologies is unique in its specific approach, they all fundamentally incorporate iteration and the continuous feedback that it provides to successively refine and deliver a software system.
- They all involve continuous planning, continuous testing, continuous integration, and other forms of continuous evolution of both the project and the software.
- They are all lightweight, especially compared to traditional waterfall-style processes, and inherently adaptable. What is more important about agile methods is that they all focus on empowering people to collaborate and make decisions together quickly and effectively.
thumb_up 2 thumb_down 0 flag 0
- An object is an instance of a class. You can create many instances of a class. A Java class uses variables to define data fields and methods to define actions.
- Additionally,a class provides methods of a special type, known as constructors, which are invoked to create a new object. Constructors are designed to perform initializing actions, such as initializing the data fields of objects.
a) Encapsulation :Encapsulation refers to keeping objects with their methods in one place. It also protects the integrity of the data.
public class Mobile { private String manufacturer; private String operating_system; public String model; private int cost; //Constructor to set properties/characteristics of object Mobile(String man, String o,String m, int c){ this.manufacturer = man; this.operating_system=o; this.model=m; this.cost=c; } //Method to get access Model property of Object public String getModel(){ return this.model; } // We can add other method to get access to other properties } b)Inheritance : In Java, you can inherit a class using the extends keyword:
public class Android extends Mobile{ //Constructor to set properties/characteristics of object Android(String man, String o,String m, int c){ super(man, o, m, c); } //Method to get access Model property of Object public String getModel(){ return "This is Android Mobile- " + model; } } c)Polymorphism :
1) Static Polymorphism (compile time polymorphism/ Method overloading) :The ability to execute different method implementations by altering the argument used with the method name is known as method overloading.
public class Overloadsample { public void print(String s){ System.out.println("First Method with only String- "+ s); } public void print (int i){ System.out.println("Second Method with only int- "+ i); } public void print (String s, int i){ System.out.println("Third Method with both- "+ s + "--" + i); } } public class PolymDemo { public static void main(String[] args) { Overloadsample obj = new Overloadsample(); obj.print(10); obj.print("Amit"); obj.print("Hello", 100); } } 2) Dynamic Polymorphism (run time polymorphism/ Method Overriding) :When you create a subclass by extending an existing class, the new subclass contains data and methods that were defined in the original superclass.
public class OverridingDemo { public static void main(String[] args) { //Creating Object of SuperClass and calling getModel Method Mobile m = new Mobile("Nokia", "Win8", "Lumia",10000); System.out.println(m.getModel()); //Creating Object of Sublcass and calling getModel Method Android a = new Android("Samsung", "Android", "Grand",30000); System.out.println(a.getModel()); //Creating Object of Sublcass and calling getModel Method Blackberry b = new Blackberry("BlackB", "RIM", "Curve",20000); System.out.println(b.getModel()); } } d) Data Abstraction :
When creating a class called Vehicle, it is know there should be methods like start() and stop() but don't know start and stop mechanism of every vehicle since they could have different start and stop mechanism e.g some can be started by a kick or some can be by pressing buttons.
The advantage of Abstraction is if there is a new type of vehicle introduced, it is just need to add one class which extends Vehicle Abstract class and implement specific methods. The interface of start and stop method would be same.
public abstract class VehicleAbstract { public abstract void start(); public void stop(){ System.out.println("Stopping Vehicle in abstract class"); } } class TwoWheeler extends VehicleAbstract{ @Override public void start() { System.out.println("Starting Two Wheeler"); } } class FourWheeler extends VehicleAbstract{ @Override public void start() { System.out.println("Starting Four Wheeler"); } } thumb_up 11 thumb_down 0 flag 0
Here are the comparing indexes on the basis of which Java and C++ can be compared :
a) Platform-independent
- C++ is platform-dependent.
- Java is platform-independent.
b) Mainly used for
- C++ is mainly used for system programming.
- Java is mainly used for application programming. It is widely used in window, web-based, enterprise and mobile applications.
c) Goto statement
- C++ supports goto statement.
- Java doesn't support goto statement.
d) Multiple Inheritance
- C++ supports multiple inheritance.'
- Java doesn't support multiple inheritance through class. It can be achieved by interfaces in java.
e) Operator Overloading
- C++ supports operator overloading.
- Java doesn't support operator overloading.
f) Pointers
- C++ supports pointers. You can write pointer program in C++.
- Java supports pointer internally. But you can't write the pointer program in java. It means java has restricted pointer support in Java. Java supports what it calls "references". References act a lot like pointers in C++. References have types, and they're type-safe. These references cannot be interpreted as raw address and unsafe conversion is not allowed.
g)Compiler and Interpreter
- C++ uses compiler only.
- Java uses compiler and interpreter both.
h) Call by Value and Call by reference
- C++ supports both call by value and call by reference.
- Java supports call by value only. There is no call by reference in java.
i) Structure and Union
- C++ supports structures and unions.
- Java doesn't support structures and unions.
j) Thread Support
- C++ has no built in support for threads. C++ relies on non-standard third-party libraries for thread support.
- Java has built in support for threads. In Java, there is a Thread class that you inherit to create a new thread and override the run() method.
k) Documentation comment
- C++ doesn't support documentation comment.
- Java supports documentation comment (/** ... */) to create documentation for java source code.
l) Virtual Keyword
- C++ supports virtual keyword so that we can decide whether or not override a function.
- Java has no virtual keyword. We can override all non-static methods by default. In other words, non-static methods are virtual by default.
m) Exception Handling
- In C++, you may not include the try/catch even if the function throws an exception.
-
Exception handling in Java is different because there are no destructors. Also, in Java, try/catch must be defined if the function declares that it may throw an exception.
n) Method overloading and operator overloading
- C++ supports both method overloading and operator overloading.
- Java has method overloading, but no operator overloading. The String class does use the + and += operators to concatenate strings and String expressions use automatic type conversion, but that's a special built-in case.
thumb_up 0 thumb_down 0 flag 0
The termWeb services describes a standardized way of integrating Web-based applications using the XML, SOAP, WSDL and UDDI open standards over an Internet protocol backbone. Components of Web Services are :
The basic web services platform is XML + HTTP. All the standard web services work using the following components
- SOAP (Simple Object Access Protocol)
- UDDI (Universal Description, Discovery and Integration)
- WSDL (Web Services Description Language)
- XML is used to tag the data, SOAP is used to transfer the data, WSDL is used for describing the services available and UDDI is used for listing what services are available. Web services allow organizations to communicate data without intimate knowledge of each other's IT systems behind the firewall.
- Unlike traditional client/server models, such as a Web server/Web page system, Web services do not provide the user with a GUI. Web services instead share business logic, data and processes through a programmatic interface across a network. The applications interface, not the users. Developers can then add the Web service to a GUI (such as a Web page or an executable program) to offer specific functionality to users.
a) XML-RPC : This is the simplest XML-based protocol for exchanging information between computers.
- XML-RPC is a simple protocol that uses XML messages to perform RPCs.
- Requests are encoded in XML and sent via HTTP POST.
- XML responses are embedded in the body of the HTTP response.
- XML-RPC is platform-independent.
- XML-RPC allows diverse applications to communicate.
- A Java client can speak XML-RPC to a Perl server.
- XML-RPC is the easiest way to get started with web services.
b) SOAP : SOAP is an XML-based protocol for exchanging information between computers.
- SOAP is a communication protocol.
- SOAP is for communication between applications.
- SOAP is a format for sending messages.
- SOAP is designed to communicate via Internet.
- SOAP is platform independent.
- SOAP is language independent.
- SOAP is simple and extensible.
- SOAP allows you to get around firewalls.
c) WSDL : WSDL is an XML-based language for describing web services and how to access them.
- WSDL is an XML based protocol for information exchange in decentralized and distributed environments.
- WSDL is the standard format for describing a web service.
- WSDL definition describes how to access a web service and what operations it will perform.
- WSDL is a language for describing how to interface with XML-based services.
- WSDL is an integral part of UDDI, an XML-based worldwide business registry.
- WSDL is the language that UDDI uses.
d) UDDI : UDDI is an XML-based standard for describing, publishing, and finding web services.
- UDDI stands for Universal Description, Discovery, and Integration.
- UDDI is a specification for a distributed registry of web services.
- UDDI is platform independent, open framework.
- UDDI can communicate via SOAP, CORBA, and Java RMI Protocol.
- UDDI uses WSDL to describe interfaces to web services.
- UDDI is seen with SOAP and WSDL as one of the three foundation standards of web services.
- UDDI is an open industry initiative enabling businesses to discover each other and define how they interact over the Internet.
thumb_up 0 thumb_down 0 flag 0
Authentication
- Authentication is used by a server when the server needs to know exactly who is accessing their information or site.
- Authentication is used by a client when the client needs to know that the server is system it claims to be.
- In authentication, the user or computer has to prove its identity to the server or client.
- Usually, authentication by a server entails the use of a user name and password. Other ways to authenticate can be through cards, retina scans, voice recognition, and fingerprints.
- Authentication does not determine what tasks the individual can do or what files the individual can see. Authentication merely identifies and verifies who the person or system is.
- Example :a driver's license or a smart card. This is the foundation for biometrics. When you do this, you first identify yourself and then submit a thumb print, a retina scan, or another form of bio-based authentication.
Authorization
- Authorization is a process by which a server determines if the client has permission to use a resource or access a file.
- Authorization is usually coupled with authentication so that the server has some concept of who the client is that is requesting access.
- The type of authentication required for authorization may vary; passwords may be required in some cases but not in others.
- In some cases, there is no authorization; any user may be use a resource or access a file simply by asking for it. Most of the web pages on the Internet require no authentication or authorization.
- Example :a night club. When you get to the door and present your I.D., you're not just claiming you are that person, but you're presenting the I.D. as proof — that's both steps in one. The result of whether or not your authentication was accepted as authentic is what determines whether or not you will be given authorization to get into the club.
thumb_up 4 thumb_down 0 flag 0
ModelViewController (MVC) is a software design pattern for developing web applications. A Model View Controller pattern is made up of the following three parts:
-
Model - The lowest level of the pattern which is responsible for maintaining data.
-
View - This is responsible for displaying all or a portion of the data to the user.
-
Controller - Software Code that controls the interactions between the Model and View.
MVC is popular as it isolates the application logic from the user interface layer and supports separation of concerns. The Controller receives all requests for the application and then works with the Model to prepare any data needed by the View. The View then uses the data prepared by the Controller to generate a final presentable response.
The MVC abstraction can be graphically represented as follows :

The model
The model is responsible for managing the data of the application. It responds to the request from the view and it also responds to instructions from the controller to update itself.
The view
A presentation of data in a particular format, triggered by a controller's decision to present the data. They are script based templating systems like JSP, ASP, PHP and very easy to integrate with AJAX technology.
The controller
The controller is responsible for responding to user input and perform interactions on the data model objects. The controller receives the input, it validates the input and then performs the business operation that modifies the state of the data model.
thumb_up 3 thumb_down 0 flag 0
In order to get a conceptual view of how the internet work, here are the steps :
Step 1: The web browser sends a request
- The first step is to verify the URL. Once the address is verified, the web browser will go through few processes.
- It will start by looking up which protocol it will use. If the URL starts by http:// it will use the HTTP protocol, if it starts withftp://, the web browser will use the FTP protocol.
- It will then search where the web server is located. For this it will use an other service of the Net: the DNS (Domain Name Server). The DNS are servers that can bring associate a domain name (eg : www.google.com ) to an IP address (216.239.39.101). This IP address is unique and therefore the server web is rapidly recognized. It is the IP address that your web browser will contact and will communicate with the HTTP or FTP server. The request will aim at obtaining the index.html page.
Step 2: The web server sends back the info
- The web server has received a request from a machine that wishes to obtain the index.html file. It will then look up the index.html file on its hard drive, take it's display and the information it holds, to finally send all that to the web browser.
- The web server knows where to send the information because since you're on the internet you also have a unique IP address.
- However if you want to access the following page: www.google.com/intl/en/about.html the web server would have look in the intl directory then in the en directory and finally would have reached the about.html file.
Step 3: The web browser processes the files
- The web browser receives the content of the index.html file. Since the extension is .html, it will be processed as a HTML file.
- At first, the navigator doesn't get the iconographic content of the page. Thus, it must, before showing the page, gather all the images that are held in the file. Of course all these requests are completely transparent to you.
- Once all the elements are gathered the page content will appear on your screen all this in few seconds.
thumb_up 8 thumb_down 0 flag 0
- Client/server architecture is a producer-consumer computing architecture where the server acts as the producer and the client as a consumer.
- Client/server architecture is a computing model in which the server hosts, delivers and manages most of the resources and services to be consumed by the client. This type of architecture has one or more client computers connected to a central server over a network or Internet connection. This system shares computing resources.
- This computing model is especially effective when clients and the server each have distinct tasks that they routinely perform. For example : In hospital data processing, a client computer can be running an application program for entering patient information while the server computer is running another program that manages the database in which the information is permanently stored.

thumb_up 2 thumb_down 0 flag 0
The following example will explain branching in git :
a) Suppose, there are two commits in git say Commit 0 and Commit 1 and master node is pointing to Commit 1.

b) Suppose, an issue has come say issue#10 and that needs to be resolved. To create a branch and switch to it at the same time, you can run the git checkout command with the-b switch:
$ git checkout -b iss10 Switched to a new branch "iss10" 
c) By resolving the issue#10, some commits needs to be done. Doing so moves the issue#10 branch forward, because it is checked out (that is, theHEAD is pointing to it).

d) Now again there arises some bugs which is needed to fix immediately. With Git, it is not required to deploy the fix along with the issue#10 changes that have been made, and no effort is required into reverting those changes before working on applying the fix to what is in production. All is to be done is to switch back to the master branch.
$ git checkout master Switched to branch 'master' At this point, the project working directory is exactly the way it was before when issue#10 occurs, and the bugfix can be worked upon now.
$ git checkout -b bugfix Switched to a new branch 'bugfix' 
e) Because the commitC3 pointed to by the branch bugfix , merged in was directly ahead of the commitC2 , Git simply moves the pointer forward. To phrase that another way, when one commit is merged with another commit that can be reached by following the first commit's history, Git simplifies things by moving the pointer forward because there is no divergent work to merge together – this is called a "fast-forward."

f) After your super-important fix is deployed, it is ready to switch back to the previous issue# 10. However, first the bugfix branch is deleted, because it is no longer needed – the master branch points at the same place.
$ git branch -d bugfix git checkout iss10 Switched to branch "iss10" 
It's worth noting here that the work that is done inbugfix branch is not contained in the files in the issue#10 branch. If the changes are needed, it can be pulled from master branch into iss10 branch by running git merge master , or changes can be integrated later.
thumb_up 2 thumb_down 0 flag 0
Database security refers to the collective measures used to protect and secure a database or database management software from illegitimate use and malicious threats and attacks.
Database security covers and enforces security on all aspects and components of databases. This includes:
- Data stored in database
- Database server
- Database management system (DBMS)
- Other database workflow applications
Database security is generally planned, implemented and maintained by a database administrator and or other information security professional.
Some of the ways database security is analyzed and implemented include:
- Restricting unauthorized access and use by implementing strong and multifactor access and data management controls
- Load/stress testing and capacity testing of a database to ensure it does not crash in a distributed denial of service (DDoS) attack or user overload
- Physical security of the database server and backup equipment from theft and natural disasters
- Reviewing existing system for any known or unknown vulnerabilities and defining and implementing a road map/plan to mitigate them
thumb_up 4 thumb_down 0 flag 0
Relation: A relation connects two entities(An entity is a small unit of data that has a unique id and a single entity type). Each relation has a single relation type. For instance there can be a "Friendship" type relation between two people named "A" and "B".
Attributes : Entities are represented by means of their properties, calledattributes. All attributes have values.
Types of Attributes :
-
Simple attribute − Simple attributes are atomic values, which cannot be divided further. Eg : a student's phone number is an atomic value of 10 digits.
-
Composite attribute − Composite attributes are made of more than one simple attribute. Eg : a student's complete name may have first_name and last_name.
-
Derived attribute − Derived attributes are the attributes that do not exist in the physical database, but their values are derived from other attributes present in the database. Eg : age can be derived from data_of_birth.
-
Single-value attribute − Single-value attributes contain single value. Eg : Aadhar Card Number, PAN Card Number.
-
Multi-value attribute − Multi-value attributes may contain more than one values. Eg : a person can have more than one phone number, email_address, etc.
thumb_up 17 thumb_down 0 flag 0
Primary Key :
- The primary key is used to identify a row of data in a table. It is used whenever it is needed to refer to a particular row.
- Primary key makes the table row unique (i.e, there cannot be 2 row with the exact same key).
- In order to identify a row, the values of a PK must be unique. The PK constraint prevent from inserting two rows with the same identical data.
- Primary key does not allow NULL value.
- A table can only have one PK and PK can be a result of multiple columns together.
Unique Key :
- Unique key constraints are used to ensure that data is not duplicated in two rows in the database.
- Unique key makes the table column in a table row unique (i.e., no 2 table row may have the same exact value).
- One row in the database is allowed to have NULL for the value of the unique key constraint.
- Unique key allows null value.
- A table but a table can have multiple unique key.
So, the basic differences are :
1. Behavior: Primary Key is used to identify a row (record) in a table whereas Unique-key is to prevent duplicate values in a column.
2. Indexing: By default Sql-engine creates Clustered Index on primary-key if not exists and Non-Clustered Index on Unique-key.
3. Nullability: Primary key does not include NULL values whereas Unique-key can include NULL values..
4. Existence: A table can have at most one primary key but can have multiple Unique-key.
5. Modifiability: You can't change or delete primary values but Unique-key values can.
thumb_up 12 thumb_down 1 flag 0
Following are the five services provided by an operating systems :
a) Program Execution
The purpose of a computer systems is to allow the user to execute programs. So the operating systems provides an environment where the user can conveniently run programs.
Following are the major activities of an operating system with respect to program management −
- Loads a program into memory.
- Executes the program.
- Handles program's execution.
- Provides a mechanism for process synchronization.
- Provides a mechanism for process communication.
- Provides a mechanism for deadlock handling.
b) I/O Operations
Each program requires an input and produces output. This involves the use of I/O. The operating systems hides the user the details of underlying hardware for the I/O. All the user sees is that the I/O has been performed without any details. So the operating systems by providing I/O makes it convenient for the users to run programs.
An Operating System manages the communication between user and device drivers.
- I/O operation means read or write operation with any file or any specific I/O device.
- Operating system provides the access to the required I/O device when required.
c) File System Manipulation
The output of a program may need to be written into new files or input taken from some files. The operating systems provides this service. The user does not have to worry about secondary storage management. User gives a command for reading or writing to a file and sees his her task accomplished. Thus operating systems makes it easier for user programs to accomplished their task.
Following are the major activities of an operating system with respect to file management −
- Program needs to read a file or write a file.
- The operating system gives the permission to the program for operation on file.
- Permission varies from read-only, read-write, denied and so on.
- Operating System provides an interface to the user to create/delete files.
- Operating System provides an interface to the user to create/delete directories.
- Operating System provides an interface to create the backup of file system.
d) Communications
There are instances where processes need to communicate with each other to exchange information. It may be between processes running on the same computer or running on the different computers. By providing this service the operating system relieves the user of the worry of passing messages between processes.
Following are the major activities of an operating system with respect to communication −
- Two processes often require data to be transferred between them
- Both the processes can be on one computer or on different computers, but are connected through a computer network.
- Communication may be implemented by two methods, either by Shared Memory or by Message Passing.
e) Error Handling
An error is one part of the system may cause malfunctioning of the complete system. To avoid such a situation the operating system constantly monitors the system for detecting the errors. This relieves the user of the worry of errors propagating to various part of the system and causing malfunctioning.
Following are the major activities of an operating system with respect to error handling −
- The OS constantly checks for possible errors.
- The OS takes an appropriate action to ensure correct and consistent computing.
thumb_up 2 thumb_down 0 flag 0
There are 5 steps required to connect to database in Java :
a) Register for the Driver Class
The forName() method of Class class is used to register the driver class. This method is used to dynamically load the driver class.
Syntax of forName() method : public static void forName(String className)throws ClassNotFoundException
b) Create the conection object
The getConnection() method of DriverManager class is used to establish connection with the database.
Syntax of getConnection() method :1) public static Connection getConnection(String url) throws SQLException
2) public static Connection getConnection(String url,String name,String password) throws SQLException
c) Create the statement object
The createStatement() method of Connection interface is used to create statement. The object of statement is responsible to execute queries with the database.
Syntax of createStatement() method : public Statement createStatement() throws SQLException
d) Execute the query
The executeQuery() method of Statement interface is used to execute queries to the database. This method returns the object of ResultSet that can be used to get all the records of a table.
Syntax of executeQuery() method :public ResultSet executeQuery(String sql) throws SQLException
e) Close the connection object
By closing connection object statement and ResultSet will be closed automatically. The close() method of Connection interface is used to close the connection.
Syntax of close() method :public void close() throws SQLException
A pseudo-code for how to connect to a database in Java :
import java.sql.*; class MysqlCon { public static void main(String args[]) { try{ //Register the driver class Class.forName("com.mysql.jdbc.Driver"); //Create the connection object Connection con=DriverManager.getConnection("jdbc:mysql://localhost:3306/db_name","username","password"); //Create the statement object Statement stmt=con.createStatement(); //Execute the query ResultSet rs=stmt.executeQuery("select * from table"); while(rs.next()) System.out.println(rs.getInt(1)+" "+rs.getString(2)+" "+rs.getString(3)); //Close the connection object con.close(); }catch(Exception e){ System.out.println(e);} } } thumb_up 6 thumb_down 0 flag 0
Yes, it is possible to implement polymorphism in structures in C.
In C we define the interface as astruct with the members.
struct DemoFunc { void (*oneParam)(int); int (*withReturn)(); }; In Java when a member function is called it has access to a variable called this , which points to the current object. In C there are no implicit parameters to functions, so needed an explicit way to communicate thisto the function. So redefining the definition of the struct,
struct DemoFunc { void (*oneParam)( struct PolyFunc *, int); int (*withReturn)( struct PolyFunc *); }; So here is a function, calledsomeFunc, which does exactly that.
void someFunc( struct Func * pf ) { int r = (pf->withReturn)( pf ); (pf->oneParam)( pf, r ); } In C the(pf->withReturn)( pf ); is saying to call the function pointed to bywithReturn from the structurepf. It also says to call it with one parameter, the value ofpf itself. The second call adds an additional parameter which is a normal function call syntax. Hence, DemoFunc now completely defines the interface we need as a base of polymorphism.
thumb_up 3 thumb_down 0 flag 0
Please read the article for detailed explanation about OOPs and its concepts.
http://quiz.geeksforgeeks.org/basic-concepts-of-object-oriented-programming-using-c/
thumb_up 8 thumb_down 0 flag 0
The main differences between Procedural Oriented Programming(POP) and Object Oriented Programming(OOPs) are :

thumb_up 0 thumb_down 0 flag 0
FRAMING :
The efficiency of any error detection scheme decreases as the length of the data increases. To detect the errors at the data link layer efficiently and easily, transmitting a small size data is a better approach.
For example : Sender maintaining 8 bit space in between the data with the aim that it will remain constant 8 bit space. But it is not possible, there can be chances that noise can modify the space, hence it will be impossible to decode the data at receiver's end. In this manner, both sender and receiver will be out of synchronization.
Data link layer (DLL) breaks the datagrams passed down by above layers and convert them into frames ready for transfer. This is called Framing. It provides two main functionalities
- Reliable data transfer service between two peer network layers
- Flow Control mechanism which regulates the flow of frames such that data congestion is not there at slow receivers due to fast senders.
Hence, the provide proper synchronization between sender and receiver, following framing types came into existence :
a) Character Count :
In this technique, DLL will add characters i.e. count value in the header to specify the number of characters in the frame.

Disadvantage : In this technique, if the count value is modified by noise then both sender and receiver will be out of synchronization. Hence this method is rarely used.
b) Character Stuffing :
Flag patterns like FLAG are stuffed between the data to maintain the synchronization between sender and receiver, hence overcome the drawbacks of Character count.
Special character like ESCis stuffed when there is data pattern equal to the Flag pattern.

(c) Bit Stuffing :
The third method allows data frames to contain an arbitrary number of bits and allows character codes with an arbitrary number of bits per character. At the start and end of each frame is a flag byte consisting of the special bit pattern 01111110 .
- Whenever the sender's data link layer encounters five consecutive 1's in the data, it automatically stuffs a zero bit into the outgoing bit stream. This technique is called bit stuffing.
- When the receiver sees five consecutive 1's in the incoming data stream, followed by a zero bit, it automatically decodes the 0 bit. The boundary between two frames can be determined by locating the flag pattern.

Advantage :
- In character stuffing, we are stuffing 8 bits , but in bit stuffing we are only stuffing 1 bit. Hence the overload size is less.
thumb_up 0 thumb_down 0 flag 0
SELECT name, salary
FROM employee
ORDER BY name, salary ;
The above query sorts only the column 'salary' in ascending order and the column 'name' by ascending order.
Input :

Output:

If you want to change the order of sorting , add DESC for descending order, For example :
SELECT name, salary
FROM employee
ORDER BY name, salary DESC;
The above query sorts only the column 'salary' in descending order and the column 'name' by ascending order.
thumb_up 6 thumb_down 5 flag 0
At first, there are five choices for the secret word.
AIM
DUE
MOD
OAT
TIE
Here is the frequency of each letter in the words:
A 2
I 2
M 2
D 2
U 1
E 2
O 2
T 2
When asked to someone, he replies that he knows the word. This means he was given a letter that is unique to a single word–the letter appears only once in the list.
He must have been given the one letter U. This means the word could not be AIM, MOD, OAT and TIE.
The secret word is DUE with two vowels (E, U).
thumb_up 0 thumb_down 0 flag 0
Please follow the below link for the full explanation. The article has full detailed explanation regarding network topologies and its types.
http://quiz.geeksforgeeks.org/network-topologies-computer-networks/
thumb_up 0 thumb_down 0 flag 0
Primary key in a table is needed because it ensures row-level accessibility. The candidate key to become a primary key should follow the below mentioned criteria:
a) The candidate key value must not be NULL value. This is an inviolate rule of the relational model as supported by ANSI, of RDBMS design, and of SQL Server.
b) No two columns can be same, hence the candidate key must be UNIQUE within its domain.
c) The candidate key should never change. It must hold the same value for a given occurrence of an entity for the lifetime of that entity.
| Company Tags (Subjective Problems) |
|---|
Source: https://practice.geeksforgeeks.org/answers/sumouli.choudhary/

0 komentar:
Posting Komentar